# Preprocessing
# One Hot Encoding
If you have a column that has four values, you could assign a value to each value.
The problem is that a model might trat value__4 is better than value_1.
To fix this, Scikit-Learn offeres one hot encoding. Each value will be one column.

Source: Wikipeida One Hot (opens new window)
ex:
from sklearn.preprocessing import OneHotEncoder
cat_encoder = OneHotEncoder()
housing_cat_1hot = cat_encoder.fit_transform(housing_cat)
cat_encoder.categories_
# Feature Scaling
# Min Max Scaling
Values are shifted and rescaled so that they can end up ranging from 0 to 1.

# Standardization (Z-Score Normalization)
Subtracts the mean form each observation and then divide by standard deviation.
Values are not bound within a certain range. Less Affected by outliers.
# Validation
# K-Fold Cross Validation
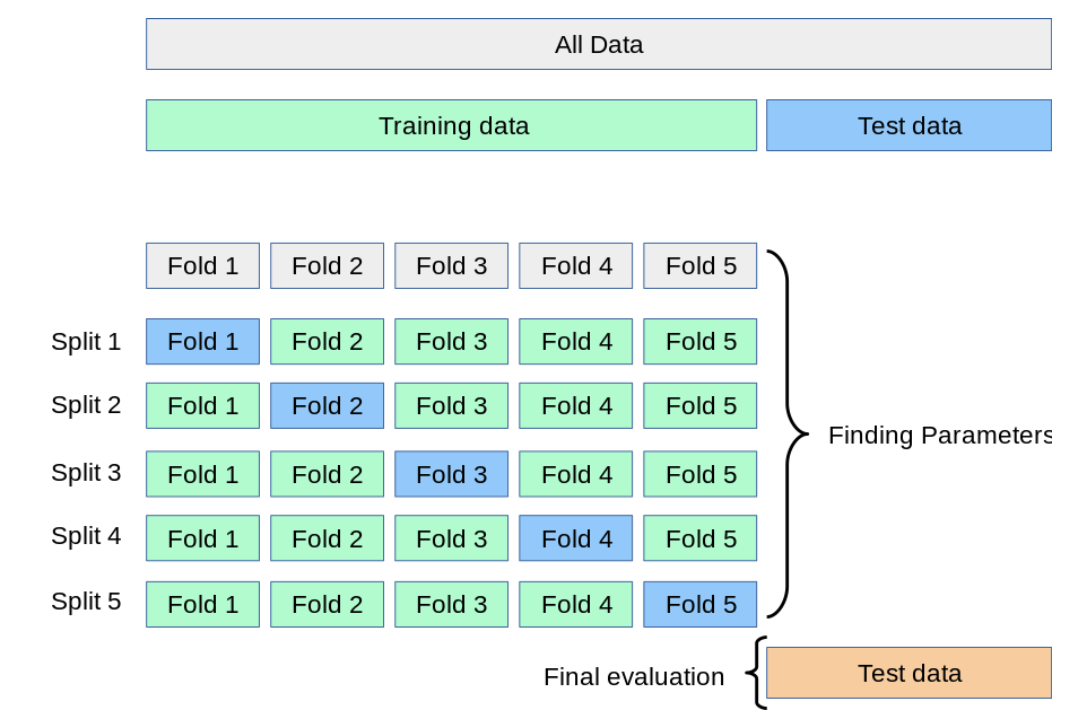
Source: Scikit-Learn: cross_validation (opens new window)
from sklearn import metrics
scores = cross_val_score(
clf, X, y, cv=5, scoring='f1_macro')
scores