# Video Recommednation
# Youtube Video Recommendations
System is composed of two neural networks (candidate generation and ranking)
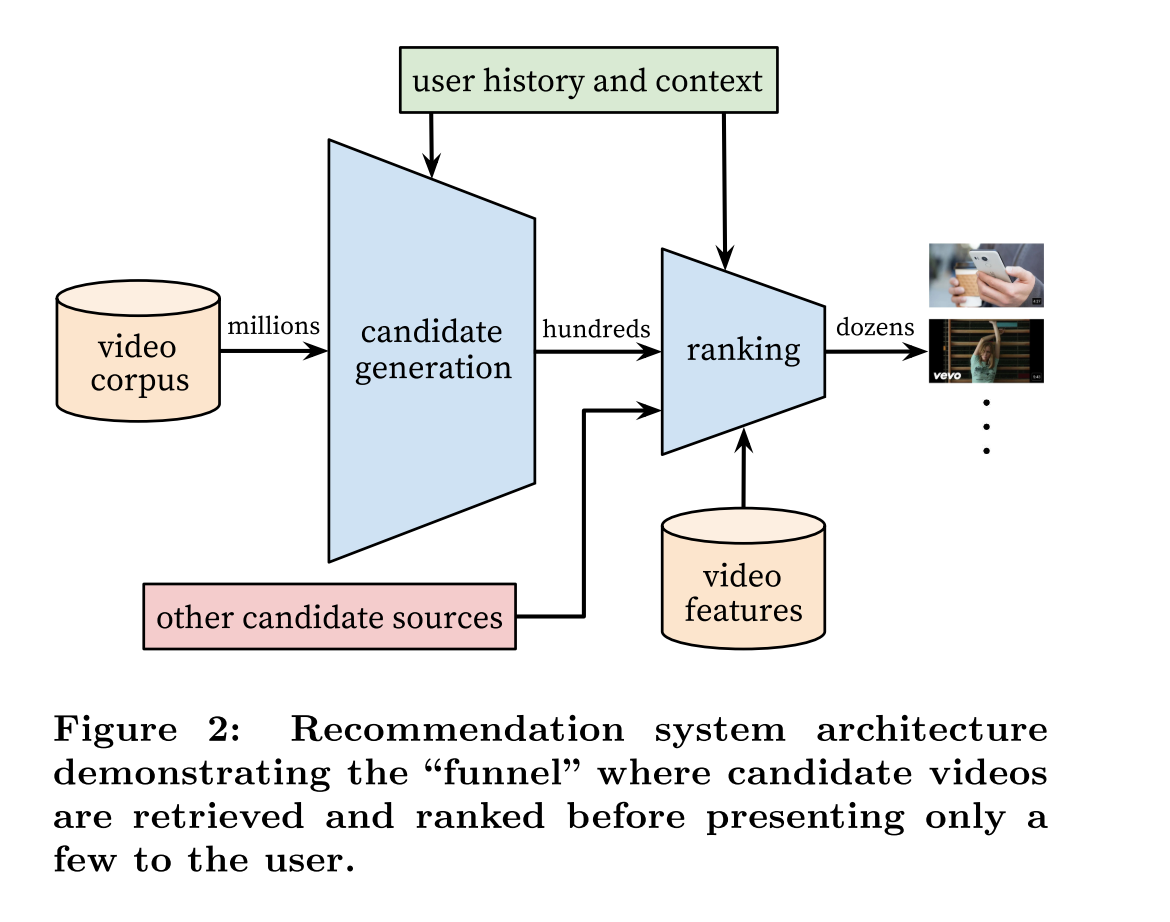
# Candidate network
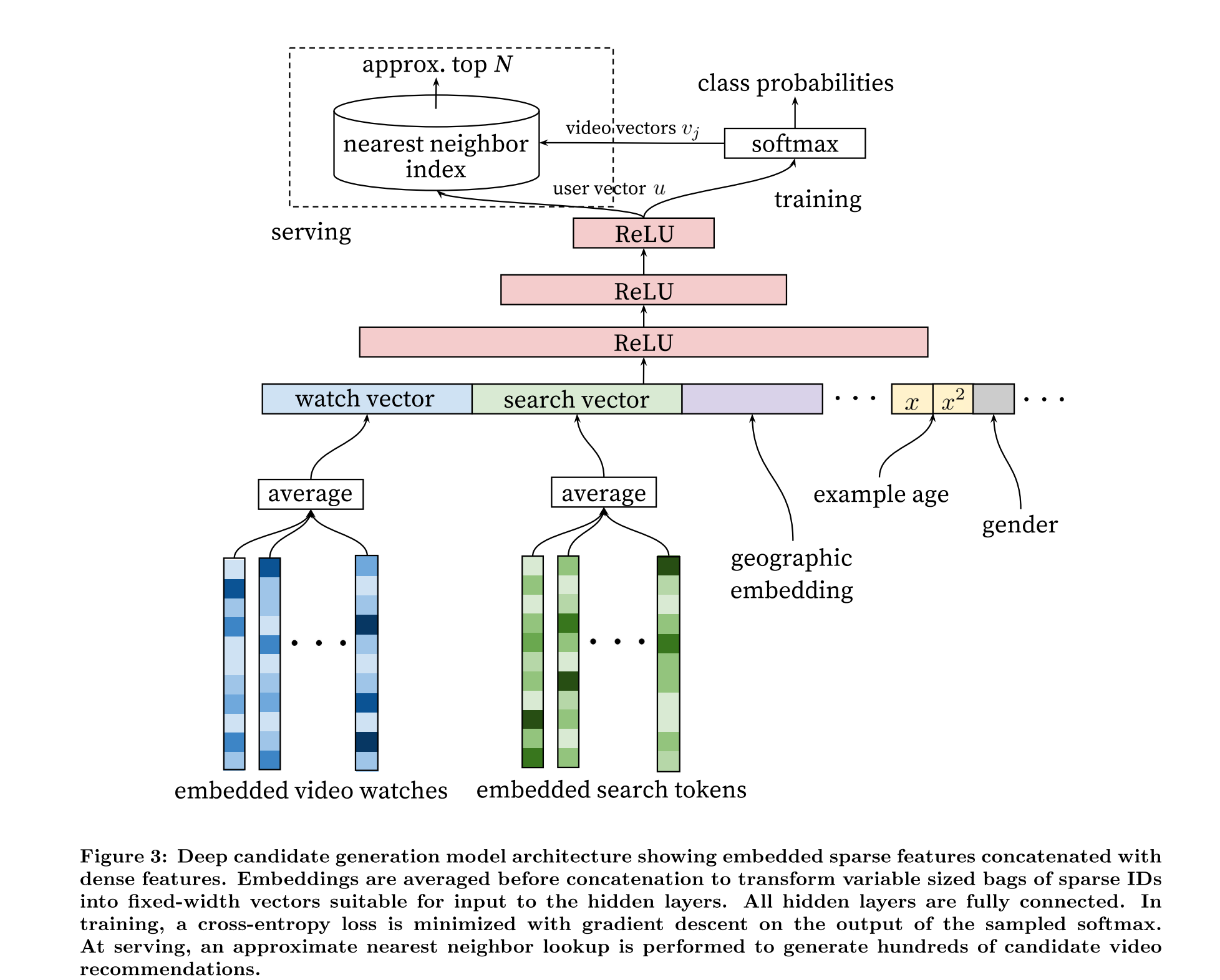
The candidate generation network takes events from the user’s YouTube activity history as input and retrieves a small subset (hundreds) of videos from a large corpus
The candidate generation network only provides broad personalization.

only use the implicit feedback of watches to train the model, where a user completing a video is a positive example.
classifier has million classes (videos)
A user’s watch history is represented by a variable-length sequence of sparse video IDs which is mapped to a dense vector representation via the embeddings.
the embeddings are learned jointly
Signal
Search history is treated similarly to watch history - each query is tokenized into unigrams and bigrams and each token is embedded.
Once averaged, the user’s tokenized, embedded queries represent a summarized dense search history.
Demographic features are important for providing priors so that the recommendations behave reasonably for new users.
The user’s geographic region and device are embedded and concatenated.
Simple binary and continuous features such as the user’s gender, logged-in state and age are input di- rectly into the network as real values normalized to [0, 1].
Recommending fresh content is important for youtube so they use age of video as signal.
a vocabulary of 1M videos and 1M search tokens were embedded with 256 floats each in a maximum bag size of 50 recent watches and 50 recent searches. The softmax layer outputs a multinomial distribution over the same 1M video classes with a dimension of 256
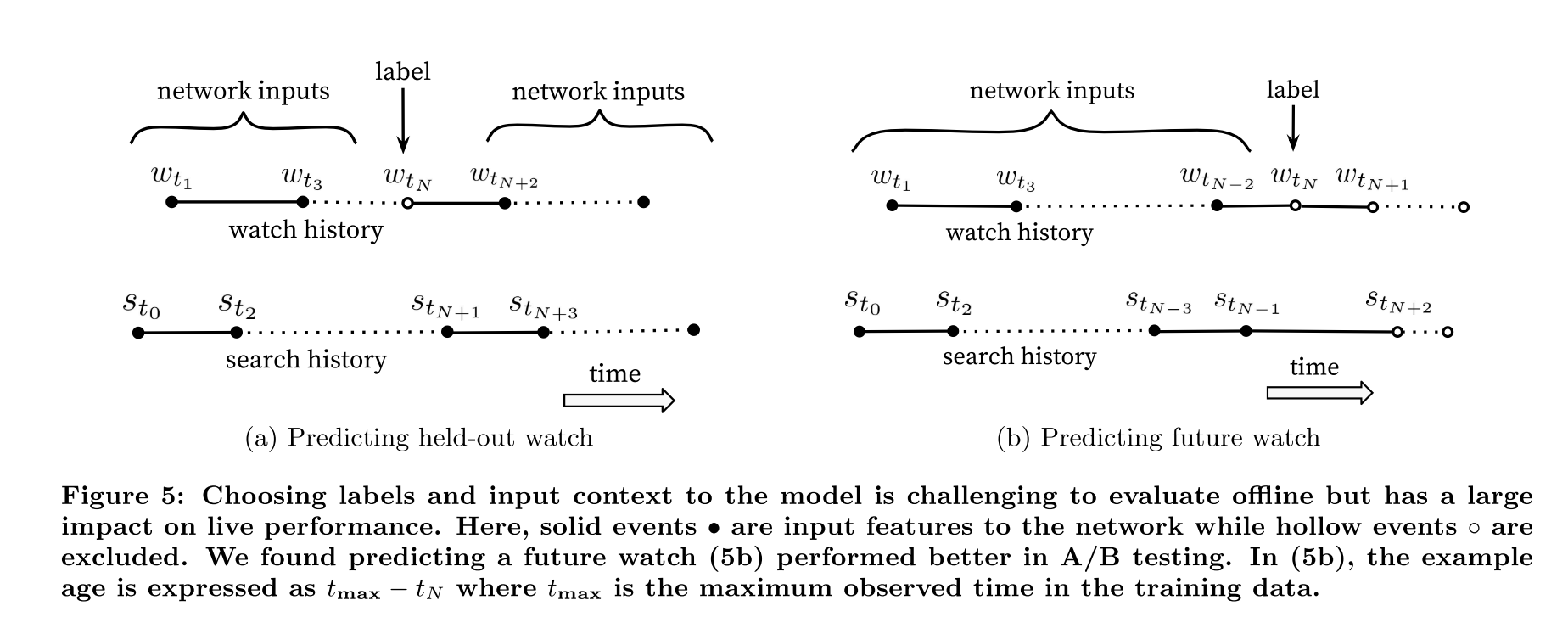
Label Generation generate a fixed number of training examples per user, effectively weighting our users equally in the loss function
# Ranking Network
The primary role of ranking is to use impression data to specialize and calibrate candidate predictions for the partic- ular user interface.
The ranking network accomplishes this task by assigning a score to each video according to a desired objective function using a rich set of features describing the video and user.
use a deep neural network with similar architecture as candidate generation to assign an independent score to each video impression using logistic regression
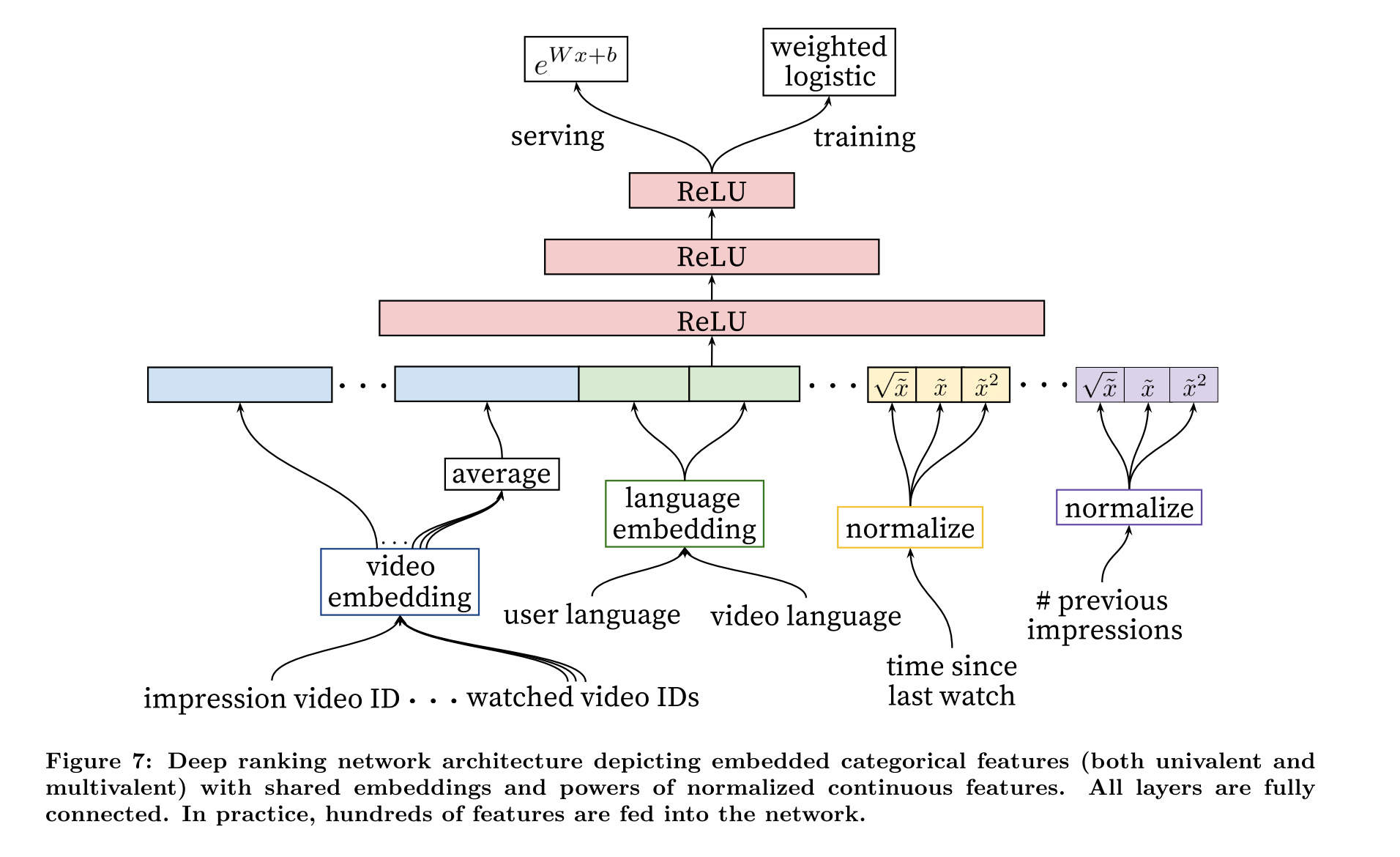
Our final ranking objective is constantly being tuned based on live A/B testing results but is generally a simple function of expected watch time per impression.
Signal
most important signals are those that describe a user’s previous interaction with the item itself and other similar items. Such as:
- user’s past history with the channel that uploaded the video being scored
- how many videos has the user watched from this channel? When was the last time the user watched a video on this topic?
These continuous features describing past user actions on related items are particularly powerful because they generalize well across disparate items.
Also propagate information from candidate generation into ranking in the form of features:
- which sources nominated this video candidate?
- What scores did they assign?
- Features describing the frequency of past video impressions are also critical for introducing “churn” in recommendations (successive requests do not return identical lists).
embedding with dimension that increases approximately proportional to the logarithm of the number of unique values. These
there exists a single global embedding of video IDs that many distinct features use (video ID of the impression, last video ID watched by the user, video ID that “seeded” the recommendation, etc.). Despite the shared embedding, each feature is fed separately into the network so that the layers above can learn specialized representations per feature.
A continuous feature x with distribution f is transformed to ˜x by scaling the values such that the feature is equally distributed in [0, 1) using the cumulative distribution.
In addition to the raw normalized feature ˜x, we also input X^2 and square root of x.
Model
model is a weighted logistic regression. However, the positive (clicked) impressions are weighted by the observed watch time on the video. Negative (unclicked) impressions all receive unit weight
If the negative impression receives a higher score than the posi- tive impression, then we consider the positive impression’s watch time to be mispredicted watch time.
# References
Deep Neural Networks for YouTube Recommendations (opens new window)
Deep Neural Networks for YouTube Recommendation | AISC Foundational (opens new window)