# Typeahead
# About

Suggestions:
- trending queries
- popular items
- context sensitive
- seasonal queries
Cleaning up of queries:
- remove long suggestions
- remove typos
- remove blacklisted / in appropriate items
- remove semantic duplicates (we don’t want to show “egg” and “eggs”, so we get the most popular version)
Why:
- help user save time / less friction
- larger basket size / better conversion
- discove new items
Goal:
- response latency < 25ms
Metrics:
- Typeahead CTR
- ATC
- mean keystroke length
- MRR
# Simple System
# Elastic Search
Use Elastic Search Auto complete
Mapping
PUT music
{
"mappings": {
"properties": {
"suggest": {
"type": "completion"
},
"title": {
"type": "keyword"
}
}
}
}
There is a special type completion.
The field we are using for suggestion is suggest
Indexing
PUT music/_doc/1?refresh
{
"suggest": [
{
"input": "Nevermind",
"weight": 10
},
{
"input": "Nirvana",
"weight": 3
}
]
}
A document, has suggest field. It can be a string or array of string, with weight.
Querying
POST music/_search?pretty
{
"suggest": {
"song-suggest": {
"prefix": "nir",
"completion": {
"field": "suggest" ,
"fuzzy": {
"fuzziness": 2
},
"size": 5
}
}
}
}
You can specify the number of results.
You can also use fuzziness to deal with typos
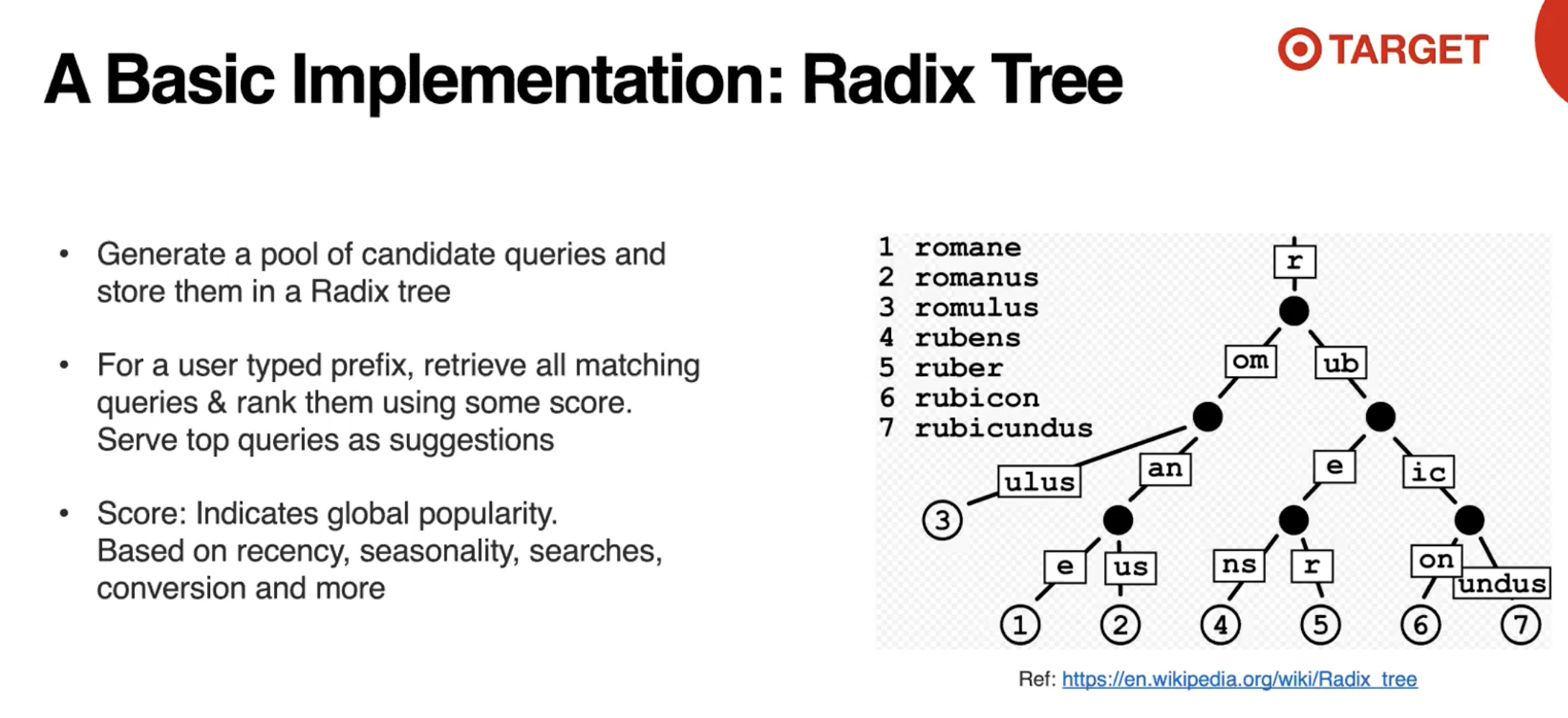
# Radix Tree
# Popularity Model
From Instacart
Data from search logs
57k words; extracted from 11.3 Million eligible products and brands leading to ~785k distinct autocomplete terms across all retailers.
# Semantic Duplication
Type of duplicates:
- exact word match (e.g. “fresh bananas” and “bananas fresh”)
- single vs plural (apple vs apples)
- compound words ( applesauce vs apple sauce)
Instacart used embedding model finetuned on their data. Using Query, prodcut conversion
An example of the query and product features would be “[QRY] milk” and “[PN] Organic 2% Reduced Fat Milk [PBN] GreenWise [PCS] Milk [PAS] organic, kosher, gluten free” respectively. In the above examples, we use [QRY], [PN], [PBN], [PCS] and [PAS] tokens to indicate the next token is a query, product name, product brand name, product categories and product attributes respectively.

Threshold was set using offline analysis and experimentation
# Cold Start
Catalog is not common among retailers ( grocery vs fashion).
Instacart has a standardized catalog that is shared amongst retailers.
Use Doc2Query to generate query candiates given produc title
# Context Aware Model
# Target
Target has a popularity model and a context aware model. And they combine with a linear score.
Features: Similarity Score between sequence and positive query, sequence and negative query Global popularity score of positive query, negative query
Final Score: w1 * similarity score + w2 * popularity score
Logic Regression was used to learn weights.
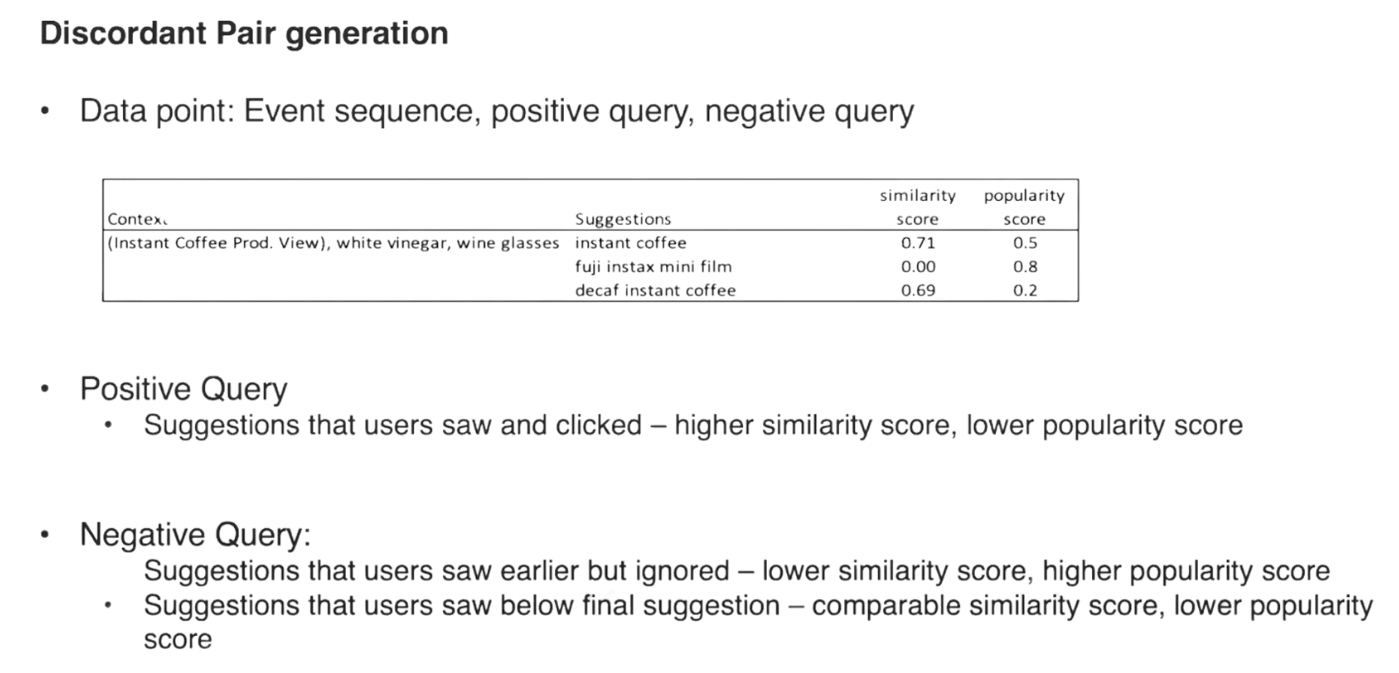
Target System
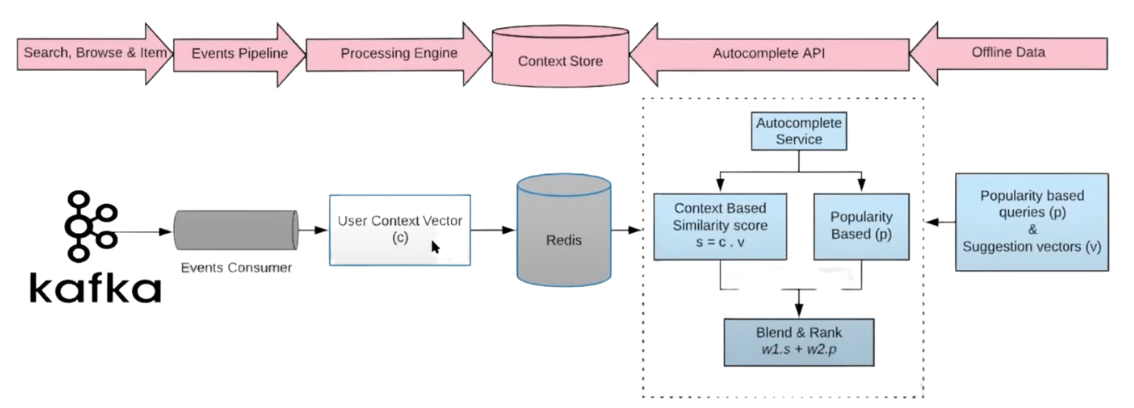 Real time system that captures user context
Real time system that captures user context
How target represents an event

model used for learning
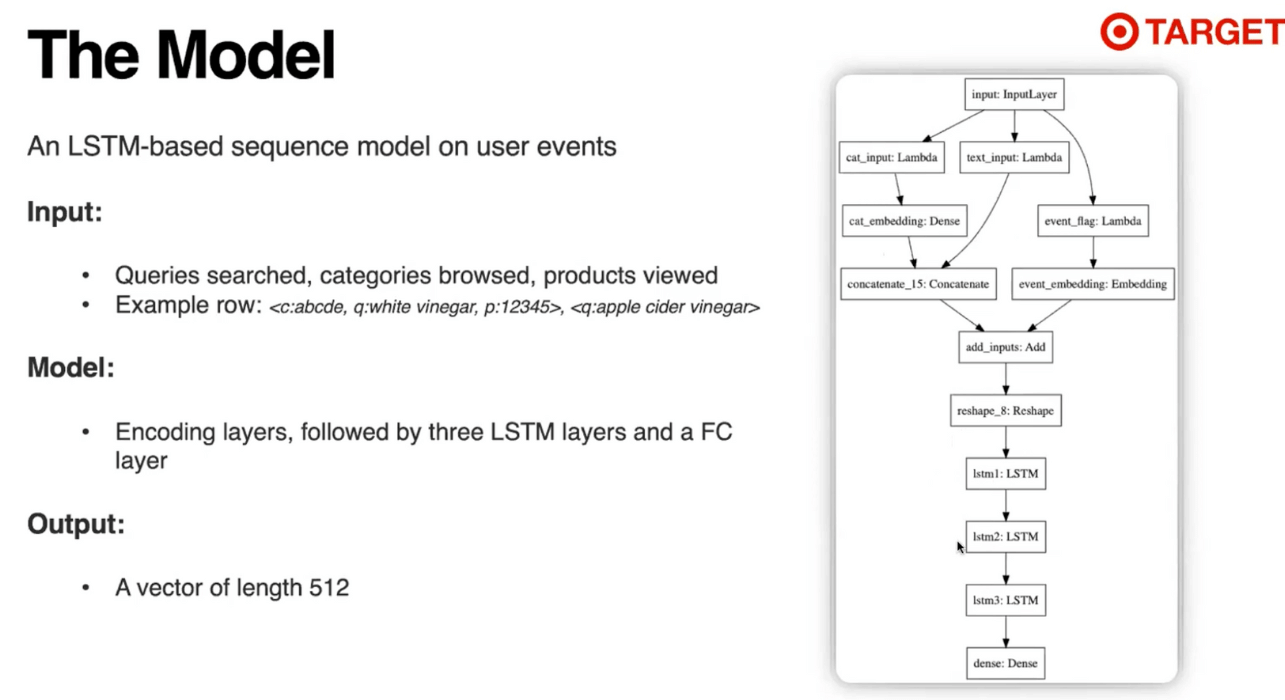
training data for above model was 4 million records; where each record is one session
# Ranking
Simple model can be ranked on query popularity. You can improve by considering context.
# Instacart

They developed a lightweight ranking algorithm modeled as a binary classification problem with a blend of query features such as popularity and prefix-query interaction features.
Top Features:
- ac_conversion_rate, measures the rate at which suggested terms are observed and clicked given a prefix.
- ac_skip_rate aims to control for position bias by modeling the rate at which top suggested terms are seen but not engaged by the user.
- is_start_match, a boolean feature to indicate whether the prefix matches from the start of the suggested term (i.e. “paper towels” matches prefix “p” from the start, but “toilet paper” doesn’t).
- is_fuzzy_match, a boolean feature to indicate whether the match is fuzzy.
- has_thumbnail, a boolean feature to indicate whether the suggestion contains a thumbnail.
- normalized_popularity, a normalized query popularity feature (as a fraction of total searches), at the retailer level.
ac: means auto complete
# Multi Objective
End goal for typeahead is to lead to ATC. You can improve typeahead conversion, but it mighht not lead to final conversion.

# Instacart
They used a model aggregation approach.
a fusion of models tuned independently for each objective.
Assume typeahead and atc are independent,
Multi-objective ranking via model aggregation — a fusion of models tuned independently for each objective. Here, we have a AC Engagement model and an Add to Cart model, trained separately and combined for final ranking.
There is a seperate Add to Cart model. It looks at hisotrical features such as
- Search Conversion Rate, the total number of searches that have at least one conversion divided by the total number of searches of that term.
- Add to Cart Rate, the total number of add to carts divided by the total number of searches of that term.
- Zero Result Rate / Low Result Rate, the rate at which a search term yields zero or a low number of results.
# Other
# Images
Show images next to suggestions

# Location Sensitivity
A user in San Diego types “Uni”. • “Univ of California, San Diego” is ok. • “Univ of California, Los Angeles” is not ok at the top
# Time Sensitivity
Ranking of candidates must be adjusted with time. “halloween” might be the right suggestion after typing “ha” in October, “harry potter” might be better any other time.
# Walmart
Given a query, month, predict seasonality score. Feature is then used for reranking.
Seasonality of a query in a given month as probability of seeing the query in that month conditioned on its occurrence. This can be estimated by the query traffic or query volume V as:
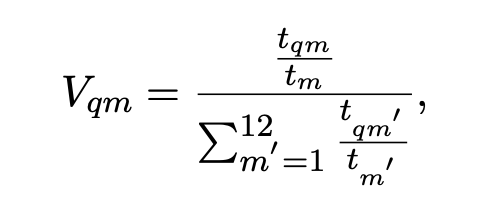
where t_qm denotes the traffic of query q in month m, and tm is the overall traffic of the month.
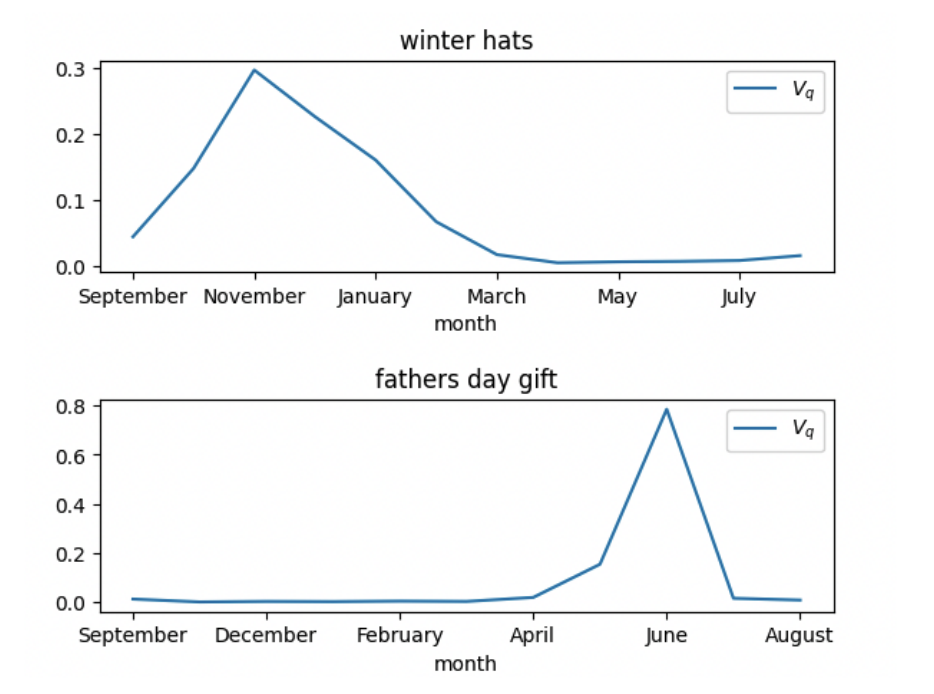
Model minimizes mean square error , predicted seasonal query volume and actual query volume.
Month value is 1 -12 . Seasonality score is from 0 - 1.
Training data is with 337k queries.
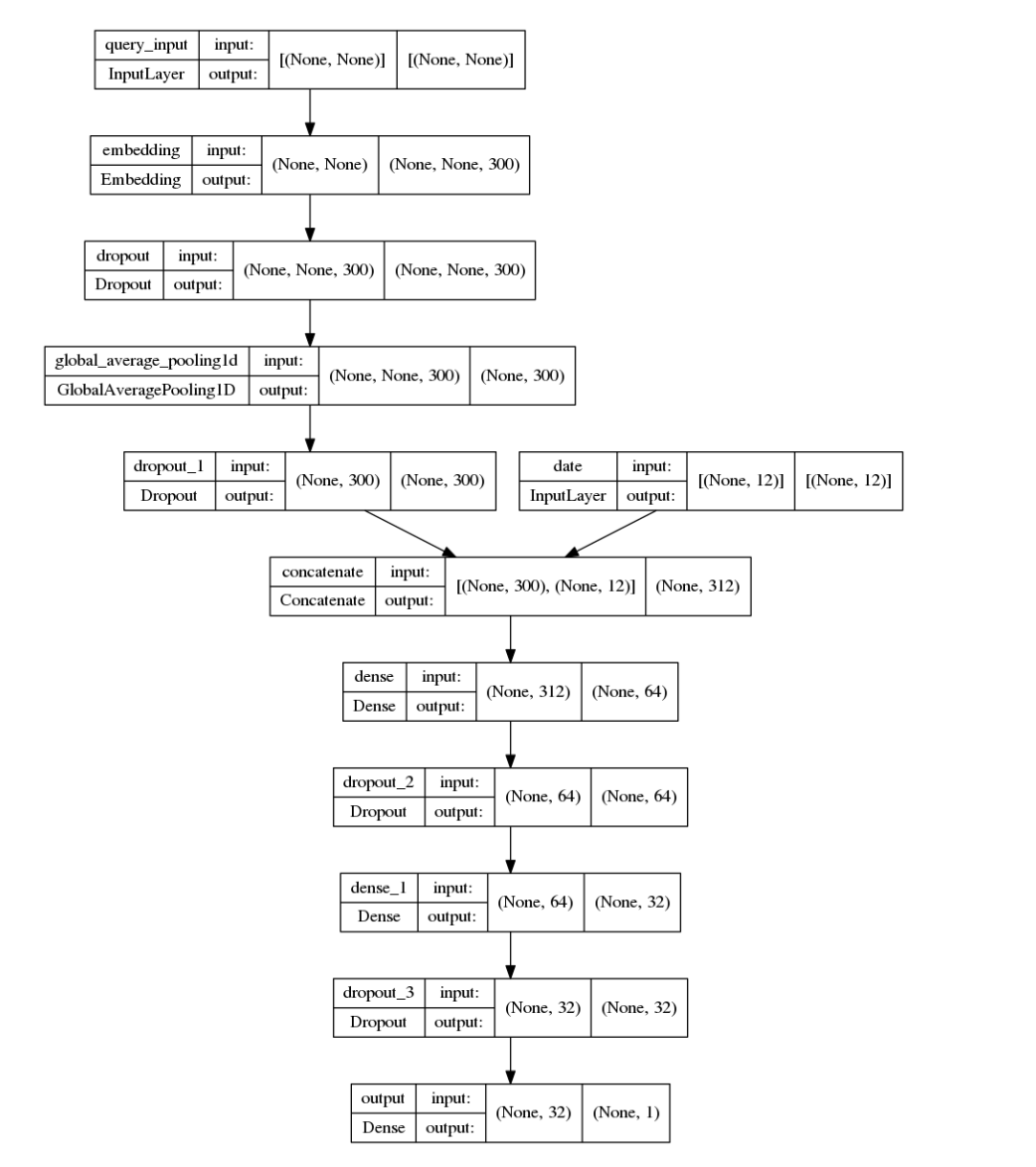
Here is the seasonal architecture.
# Ghosting
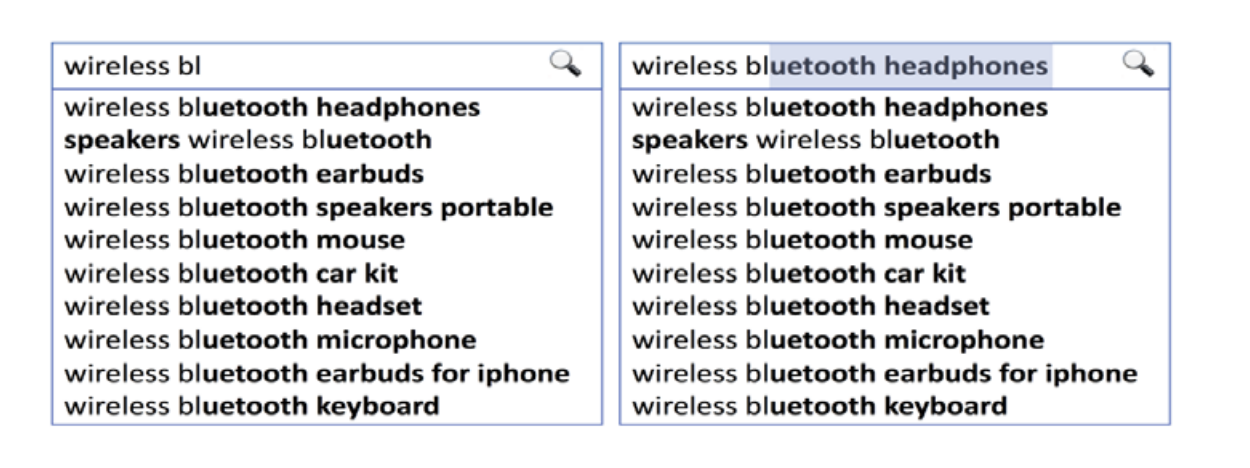
Ghosting: auto-completing a search recommendation by highlighting the suggested text inline i.e., within the search box.
# Non prefix matches
If Q is “shrimp dip rec”, then a plausible completion found by prefix-search could be “shrimp dip recipes”.
A multiterm prefix-search could return, instead, “shrimp bienville dip recipe” or “recipe for appetizer shrimp chipolte dip”
# References
Elastic Search Suggesters (opens new window)
An Embedding-Based Grocery Search Model at Instacart (opens new window)
How to build autocomplete search for e-commerce with Tejaswi Tenneti / instacart (opens new window)