# Large Scale Training
# Baisc Models
# Tree Based Model
Random Forest Models can be trained indenpendantly.
Xgboost, because it is iteratively can't build on parallel. What could be done is deciding which feature to split on, can be deon in parallel.
# Matrix Factorization
Alternating Least Square
Alternate between re-computing user-factors and item-factors, and each step is guaranteed to lower the value of the cost function.
# Logistic Regression
Each node compute mini batch on different set of data. Then the master node averages the gradient updates.
df = spark.read.parquet("cancellation.parquet")
from pyspark.ml.feature import VectorAssembler
assembler = VectorAssembler(
inputCols = ['month_interaction_count'
,'week_interaction_count','day_interaction_count']
)
df = asselmber.transform(df)
df = df.withColumn("label",F.col("cancelled_within_week"))
from pyspark.ml.classification import LogisiticRegression
df = df.cache()
train_data, test_data = df.randomSplit([0.6,0.4])
lr = LogisticRegression(maxIter=10)
lrModel = lr.fit(train_data)
predictions = lrModel.transform(test_data)
# Deep Learning Models
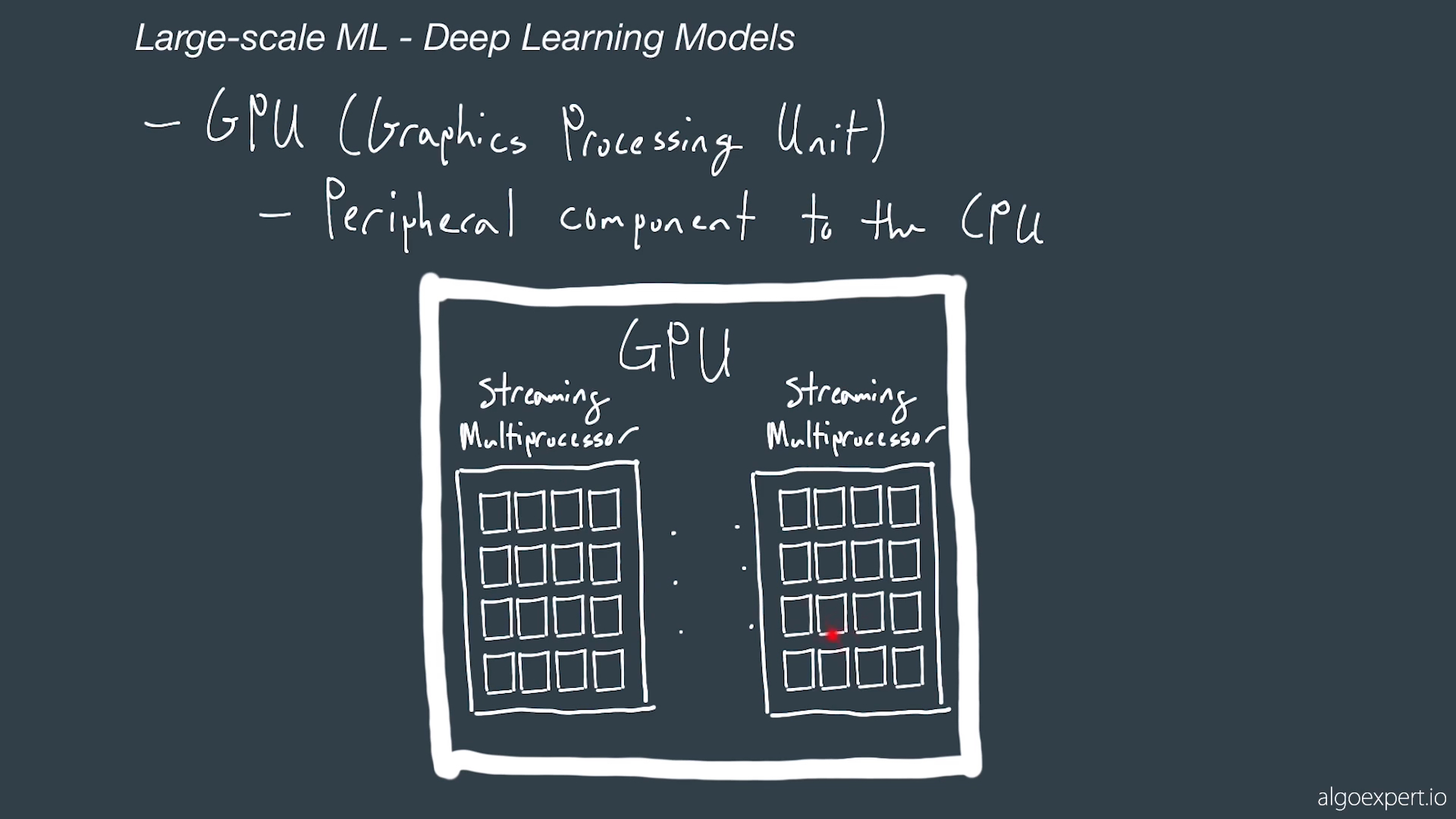
# GPU
- gpu have stream processor which have a lot of cores
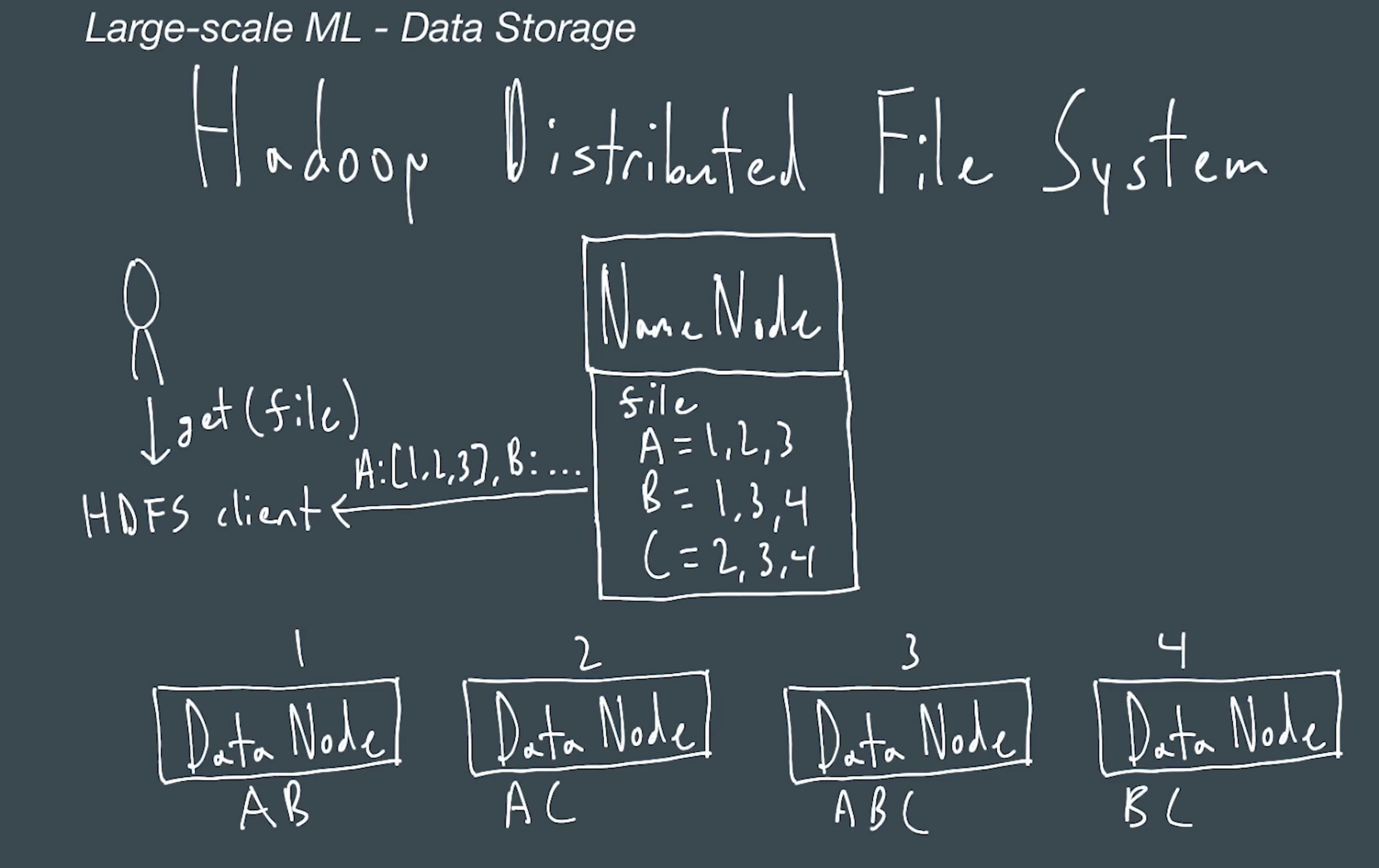
What if data can't fit in memory ?
For large models, we can have one parameter server and multiple gpus training on a portion of the data. The Gpu will send weight gradients to the master parameter server.
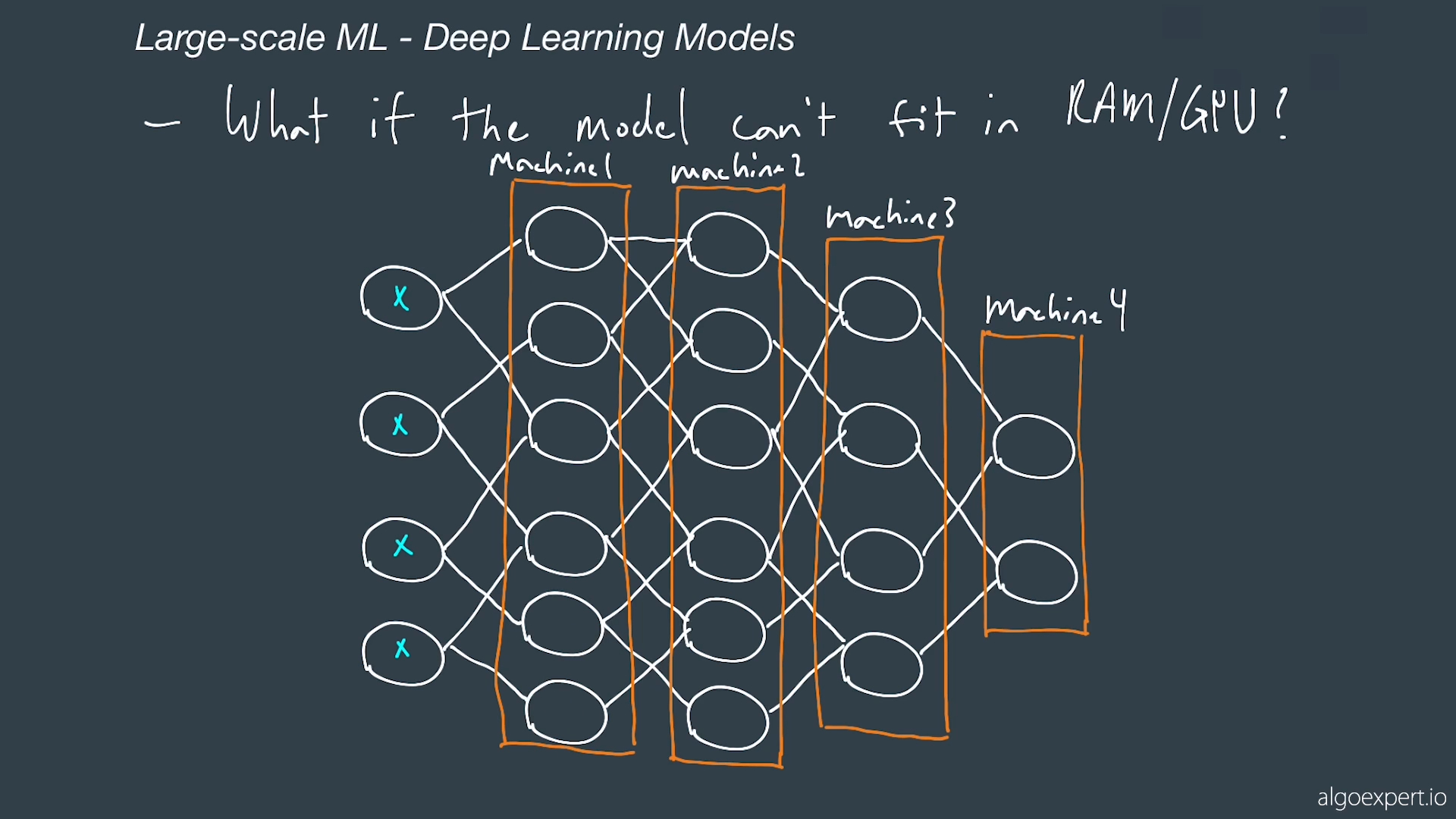
What if model can't fit in memory
You could split portions of the network in multiple machines.
Here we split among the layers
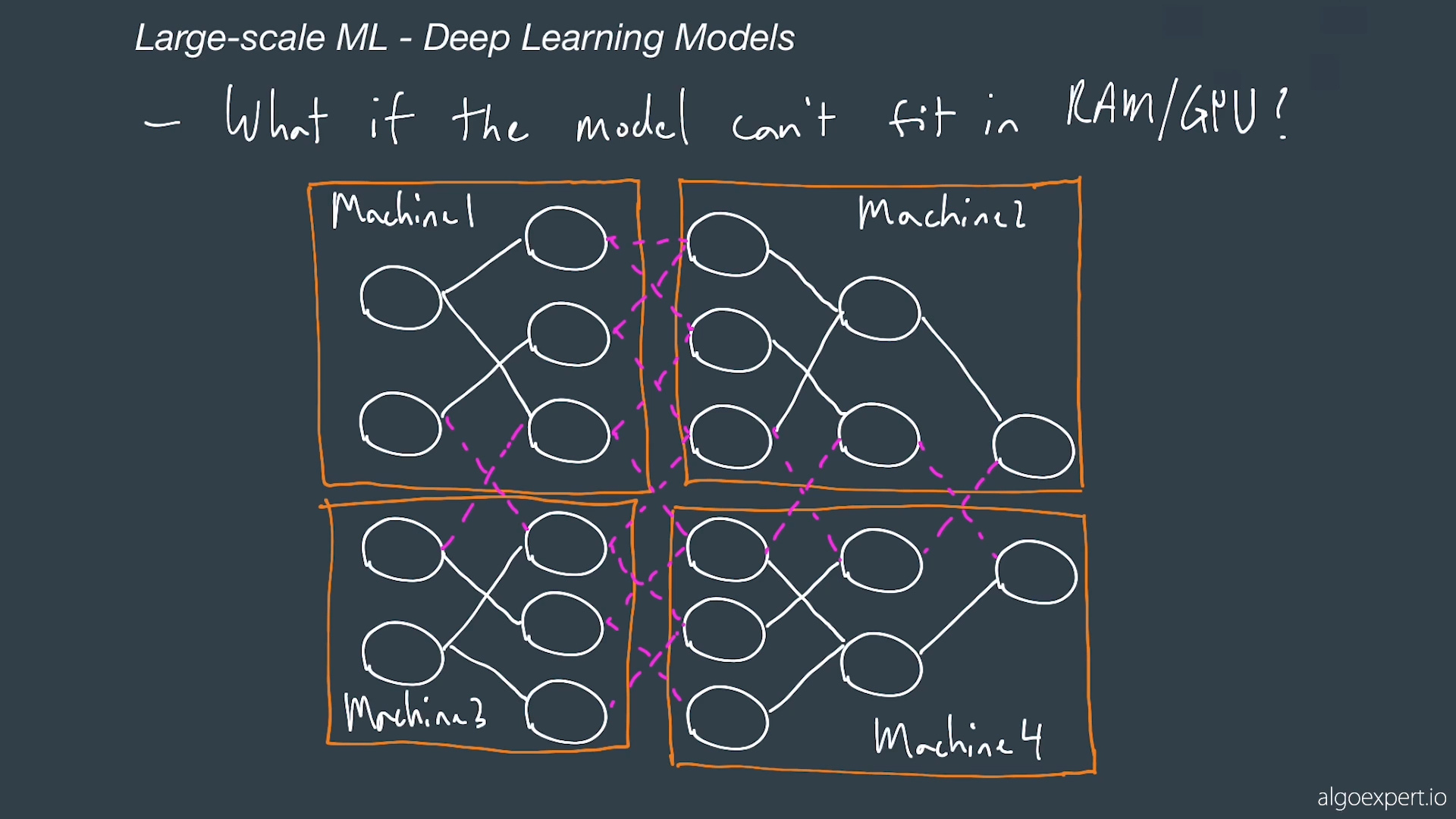
Here we split where each layer is in a machine
NVLink (opens new window) is a wire-based communications protocol for near-range semiconductor communications developed by Nvidia that can be used for data and control code transfers in processor systems between CPUs and GPUs and solely between GPUs.
InfiniBand (opens new window) is a computer networking communications standard used in high-performance computing that features very high throughput and very low latency. It is used for data interconnect both among and within computers
# Ring All-Reduce
Two Phases:
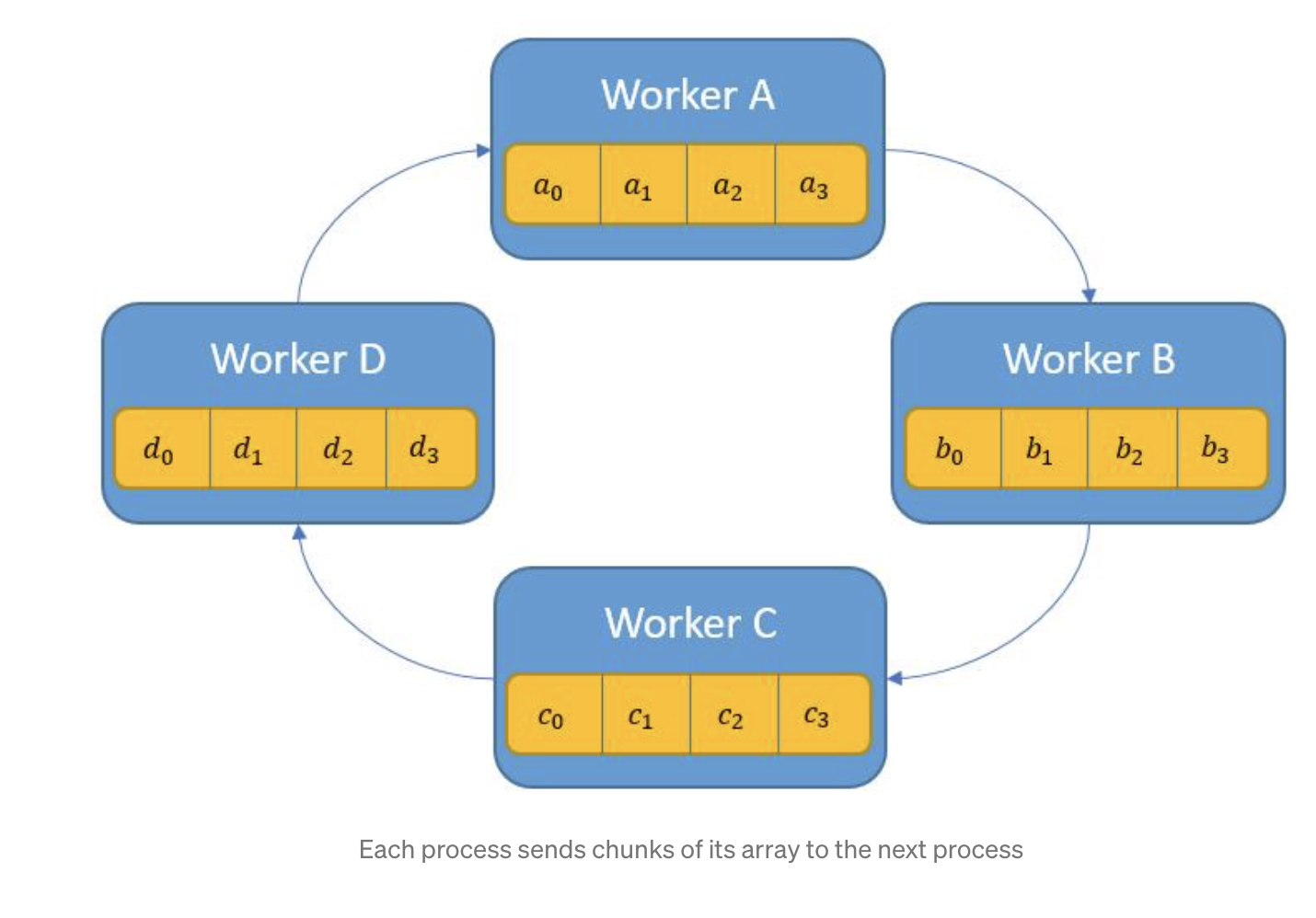
- Share Reduce Phase
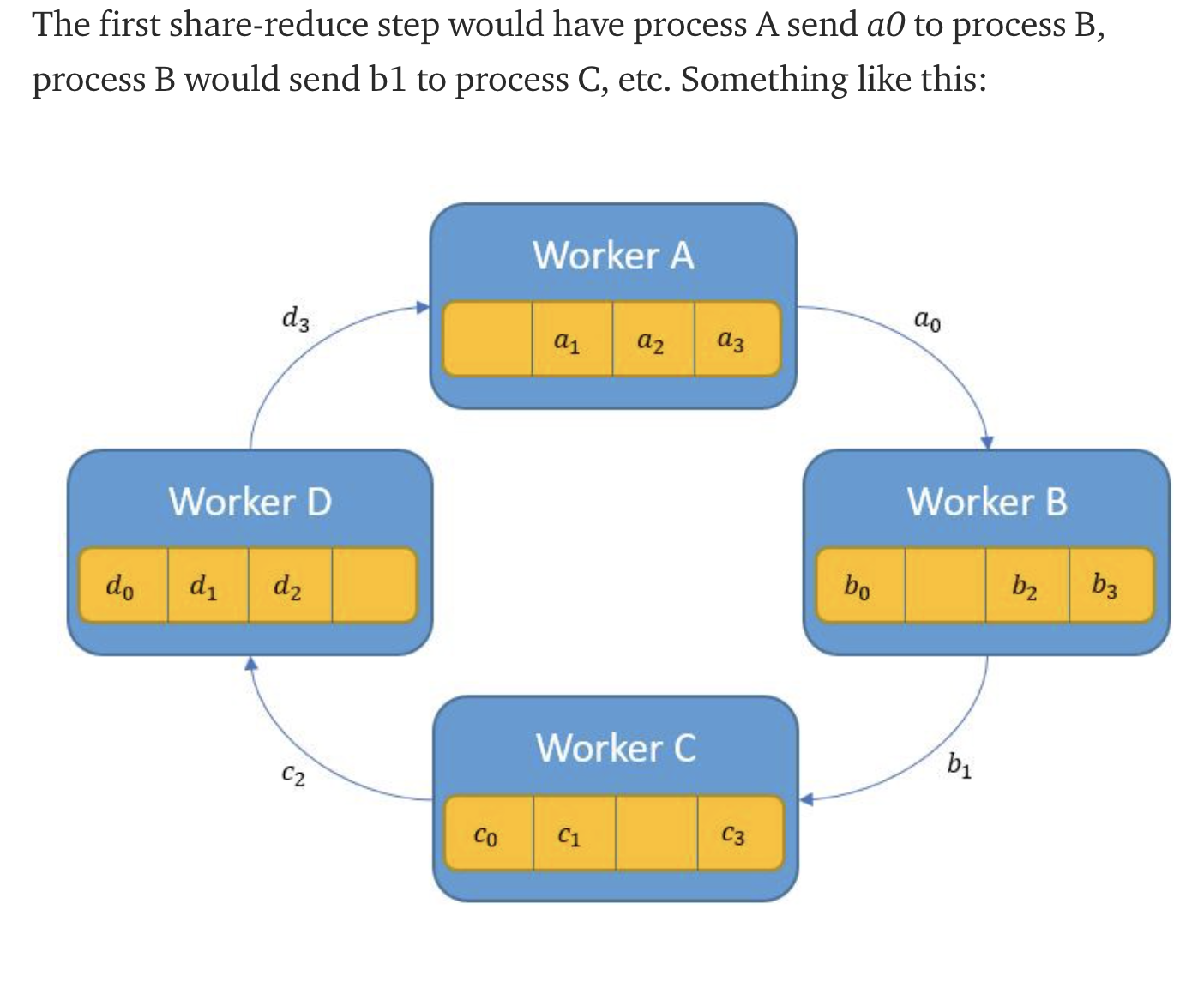
- each process p sends data to the process (p+1) % p ... So Process A will send to process B, etc.
- the array of data of length n is divided by p, each one of these chunks will be indexed by i going forward.
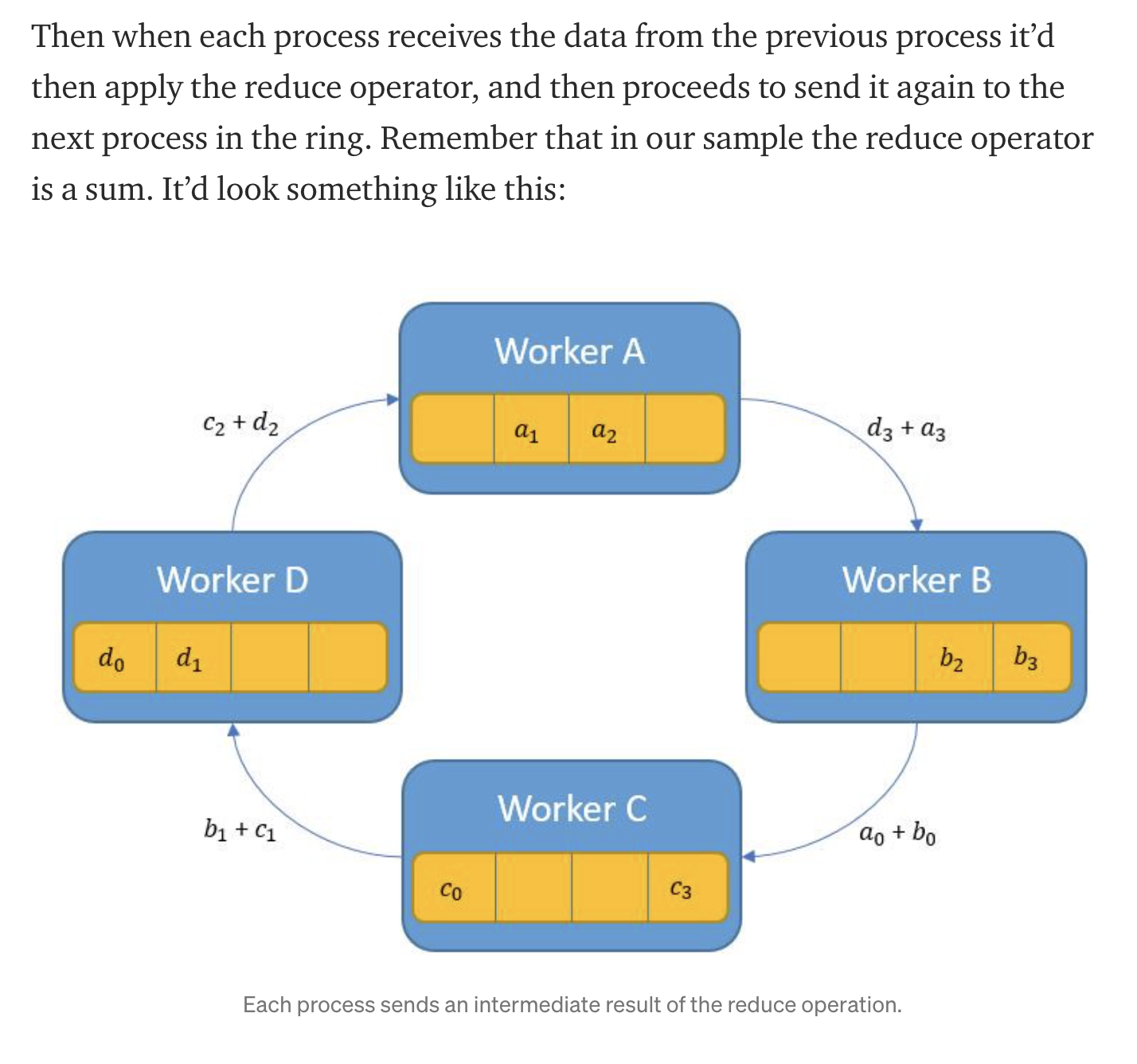
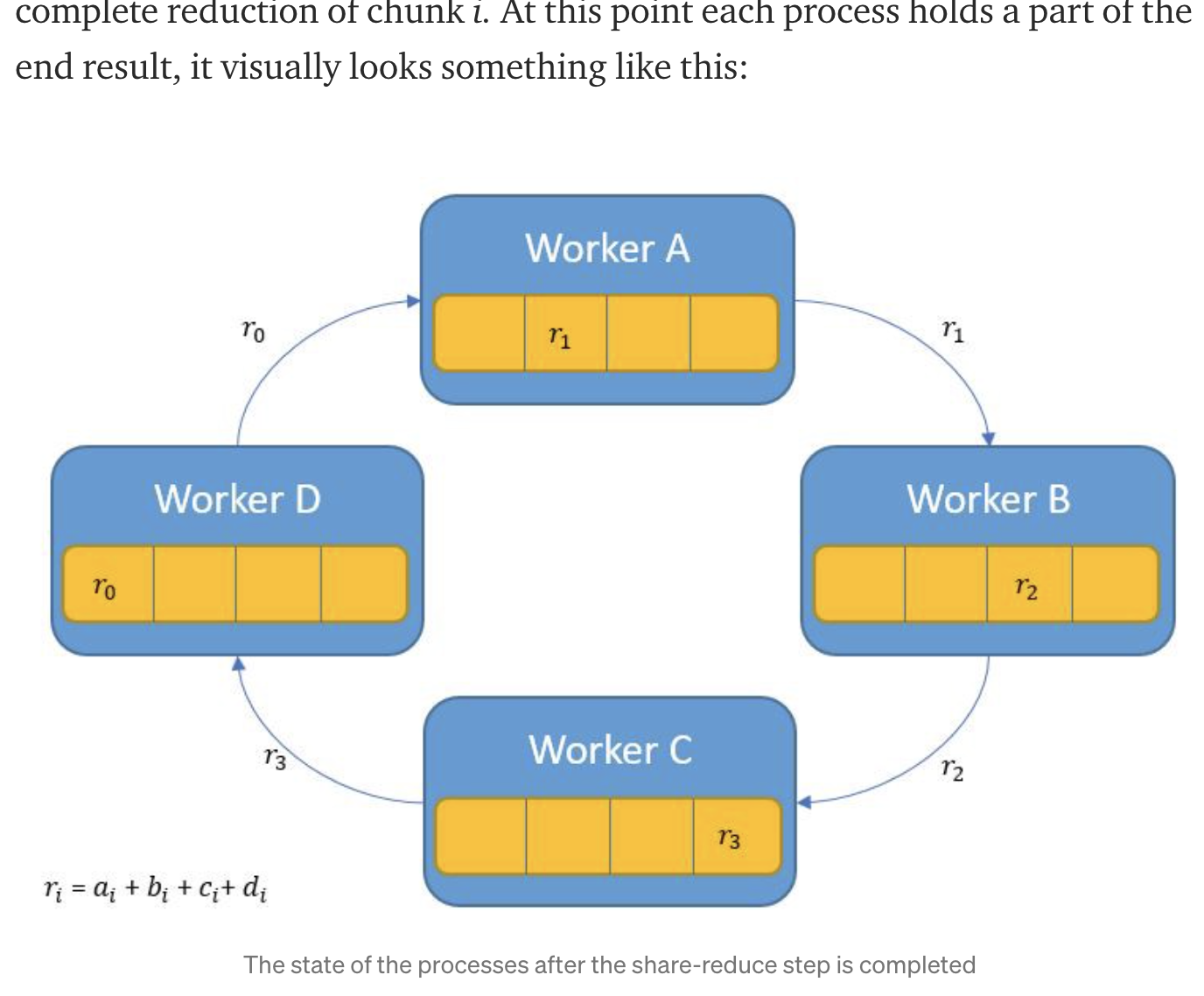
- Share Only Phase
- shares data similar to step one but doesn't apply reduction

Uber's Horovord implements this.
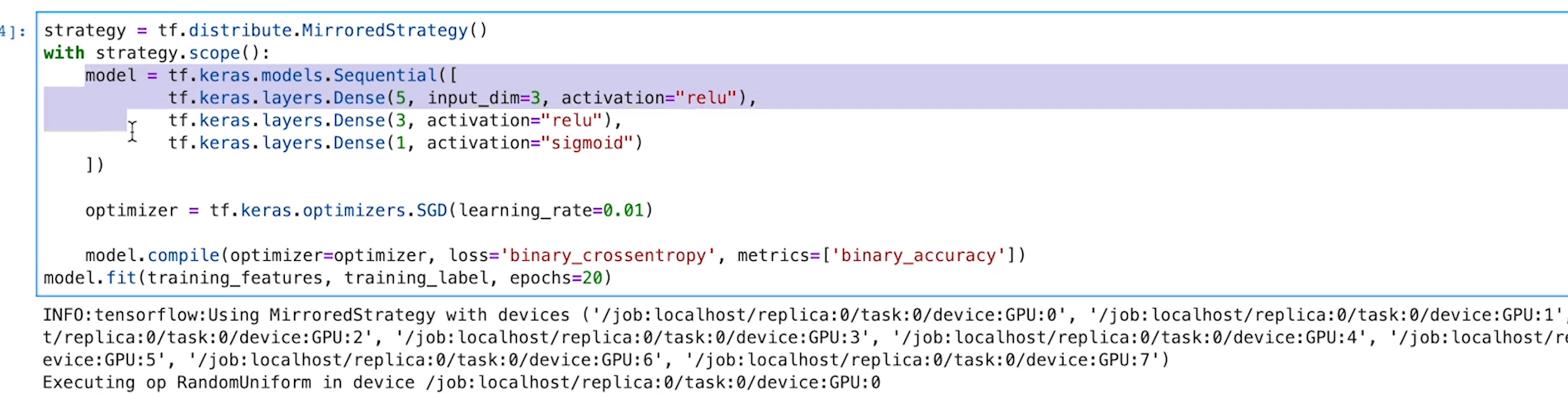
# Code
# Using multiple gpus
Here is code sinppet to use multiple gpus in tensoeflow