# Data Support
# Data Ingestion
# Streaming Ingestion
Types of Streaming Ingestions:
- Clickstream
- Change Data Capture
- Live Video
Clickstream Schema
- Datetime
- user agent
- user id if logged in)
- request details (get/details/video id)
- session id (cookie, helps tie clickstream entries)
- ip address
- referrer (google, facebook, etc)
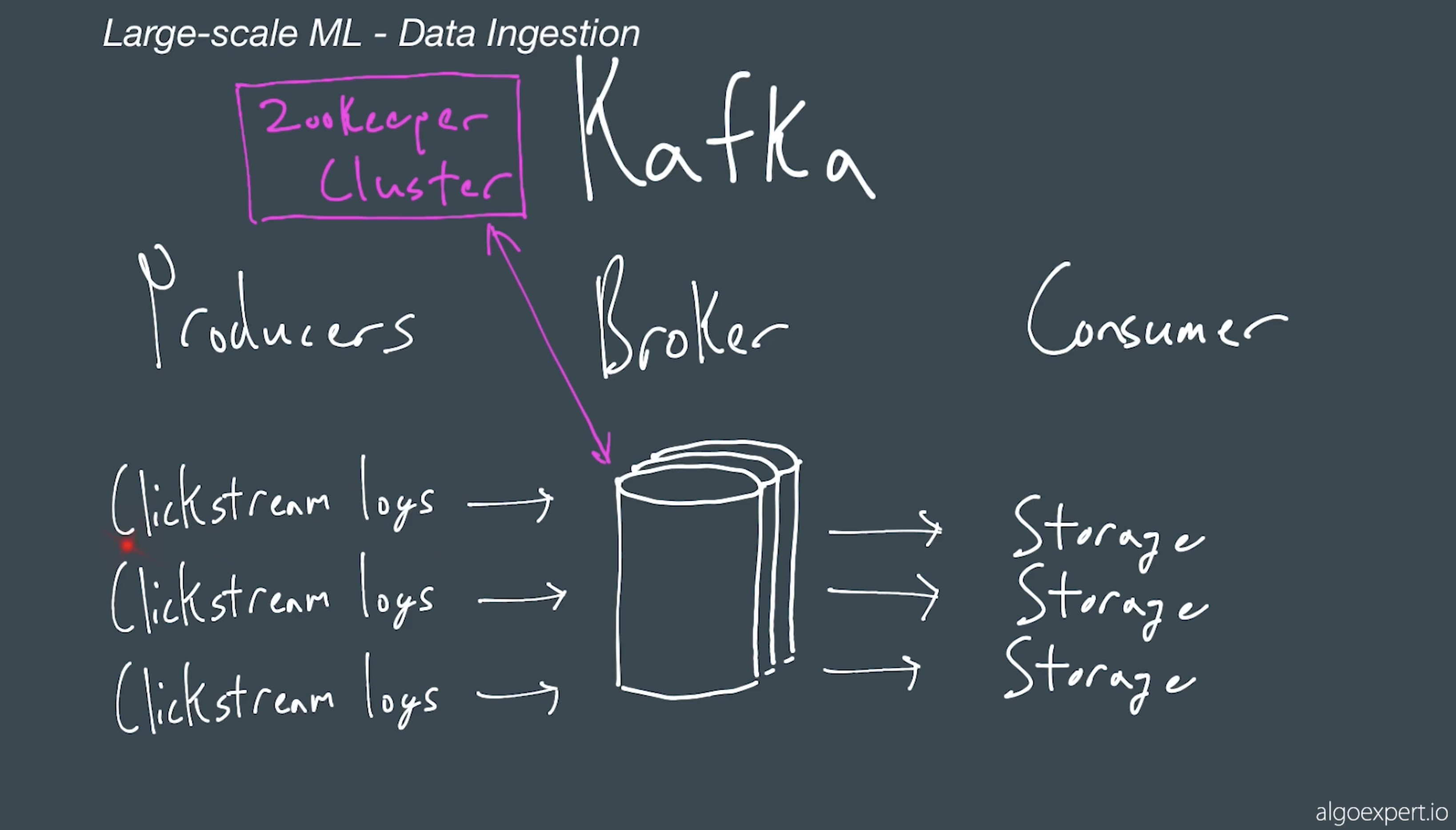
ClicklStream Tools Kafka logs will be send to producers clickstream logs will be send to topics. Topics are parittioned in brokers
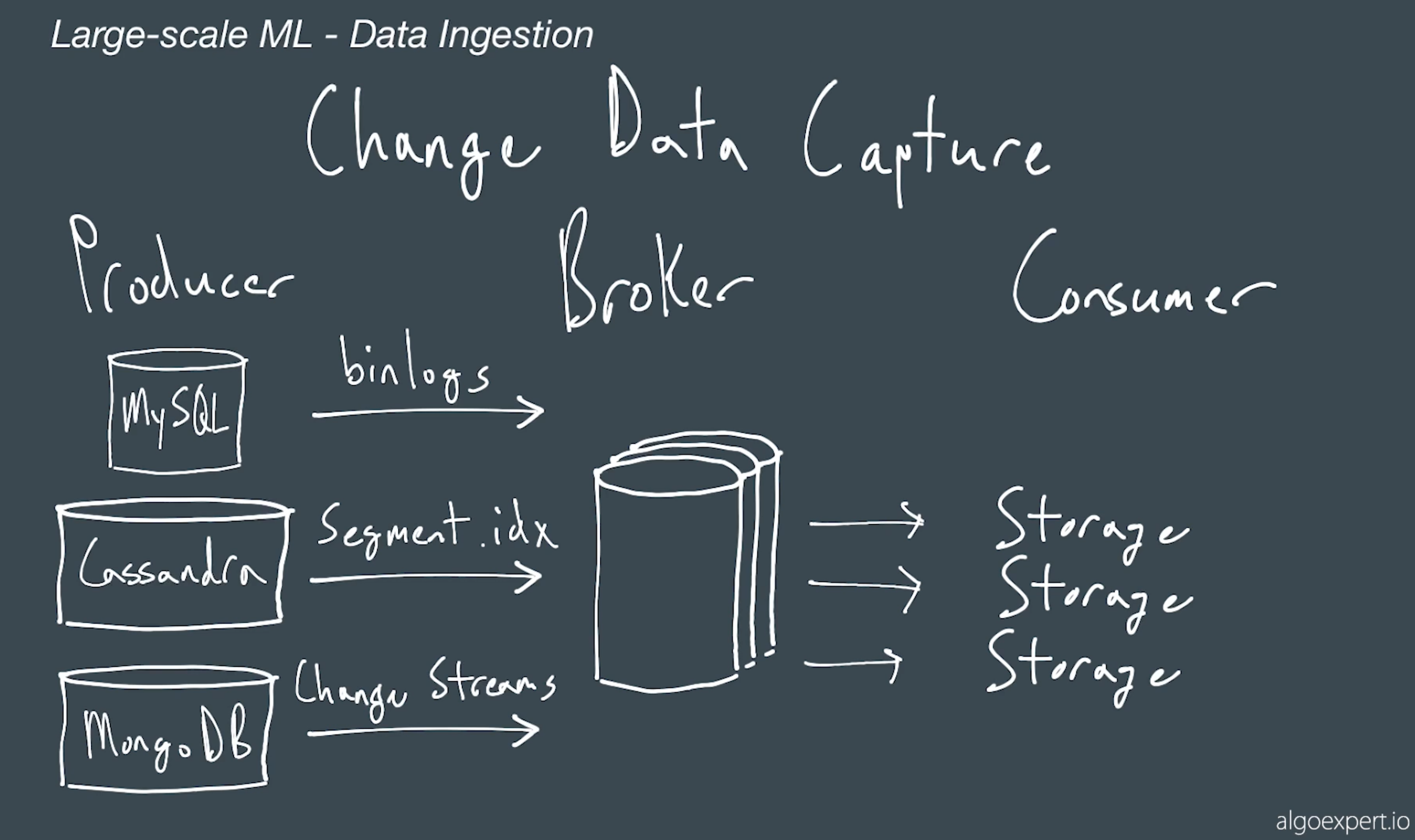
# Change Data Capture
- current user database only has current state; cant use this to understand why user left
- CDC, keep a historical record of the log
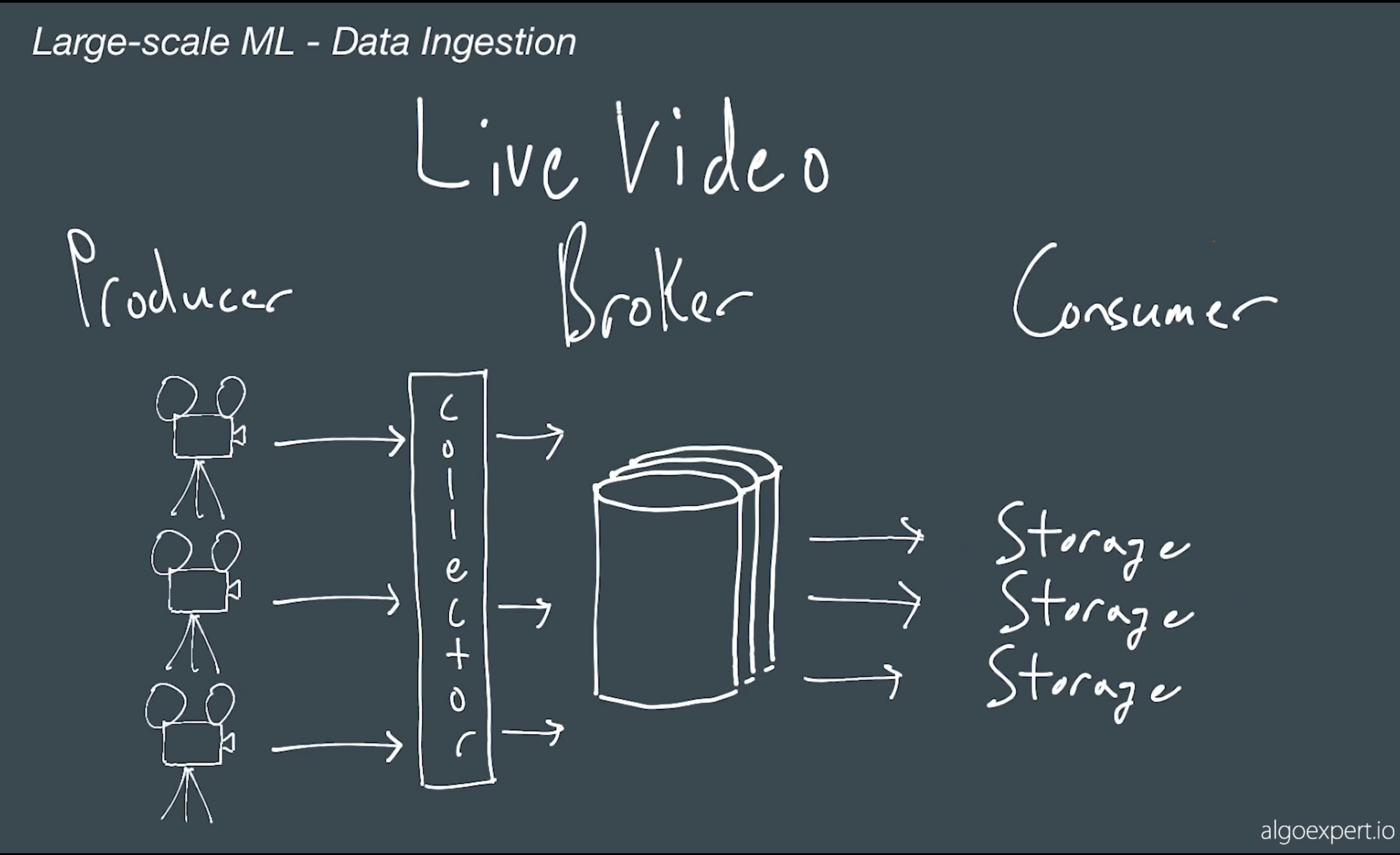
# Live Video
- ingesting video content from traffic camers, security cameras, video streaming services
- Live Video Broker
camera send video to some collector collector will comprress break out frames .. send to broker
# Batch Ingestion
- periodic Database snapshot
- useful when onboarding a new daabase to be ingested
# Data Storage
# HDFS
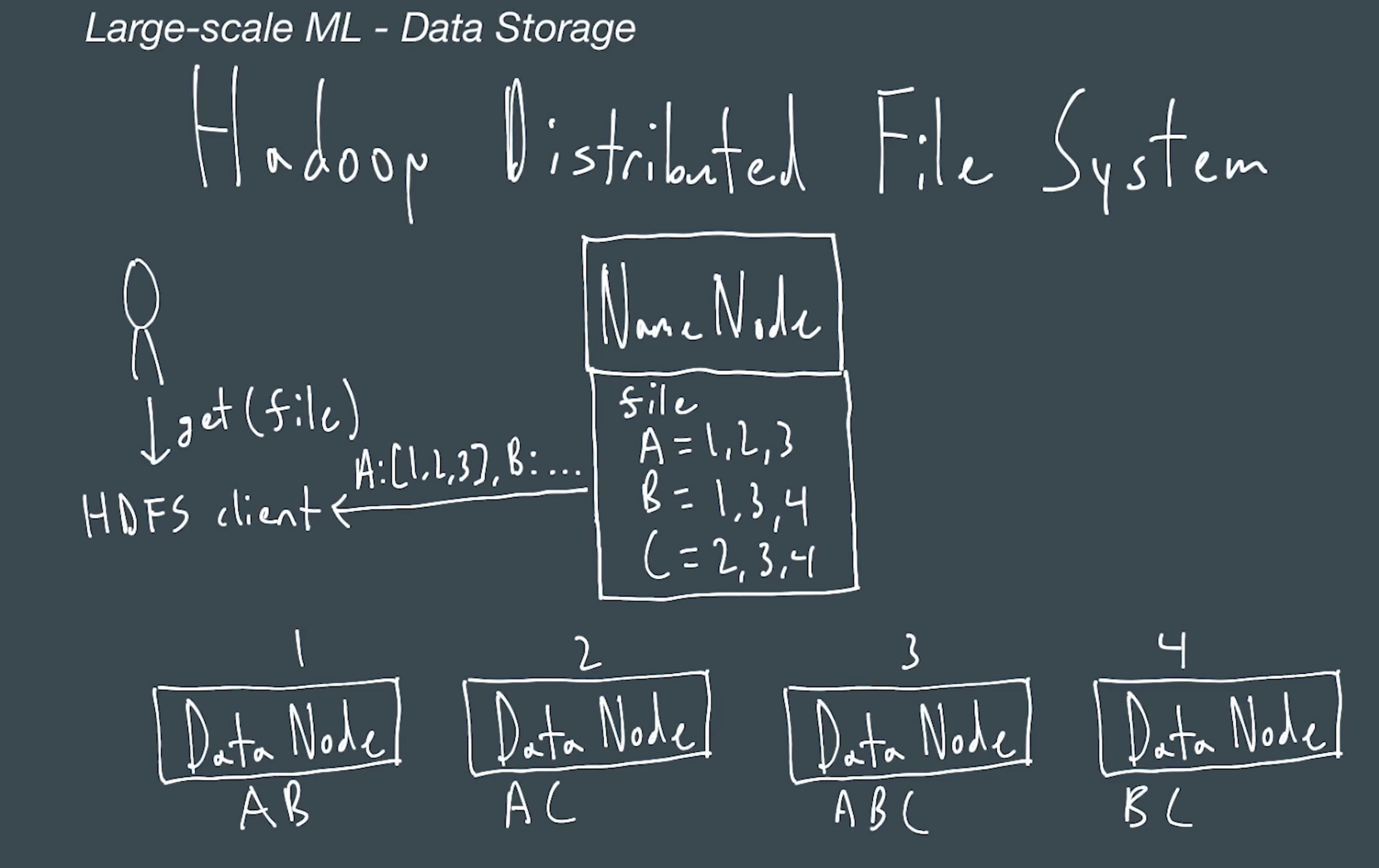
HDFS has active and passive name node.
By default , hadoop has a replciation factor of 3 for each block.
In haddop 3, it uses Reed-Solomon (RS) encoding (opens new window) to encode the file so it can reiver lost files.
# Avro vs Parquet
Avro:
- row oriented
- good for queries that need all colcumns
- good for heavy write load
- json schema supports evolution
Parquet:
- column oriented
- good for heavy read load where only some columns is needed
- good for spare data
# Data processing
Apache Spark and Apache Yarn
- Yarn (Yet Another Resource Negotiator)
- scheduler allocates cluster resource
- application manager accepts jobs to be run on cluster
- Node Manager (per node)
- negotiates with resource manager for resources requested by Applicaition Master ( AM)
- Application Master
- negotiates with the scheduler for containers
- Containers
- abstraction representing (Ram, CPU, Disk)
# Data Orchhestration
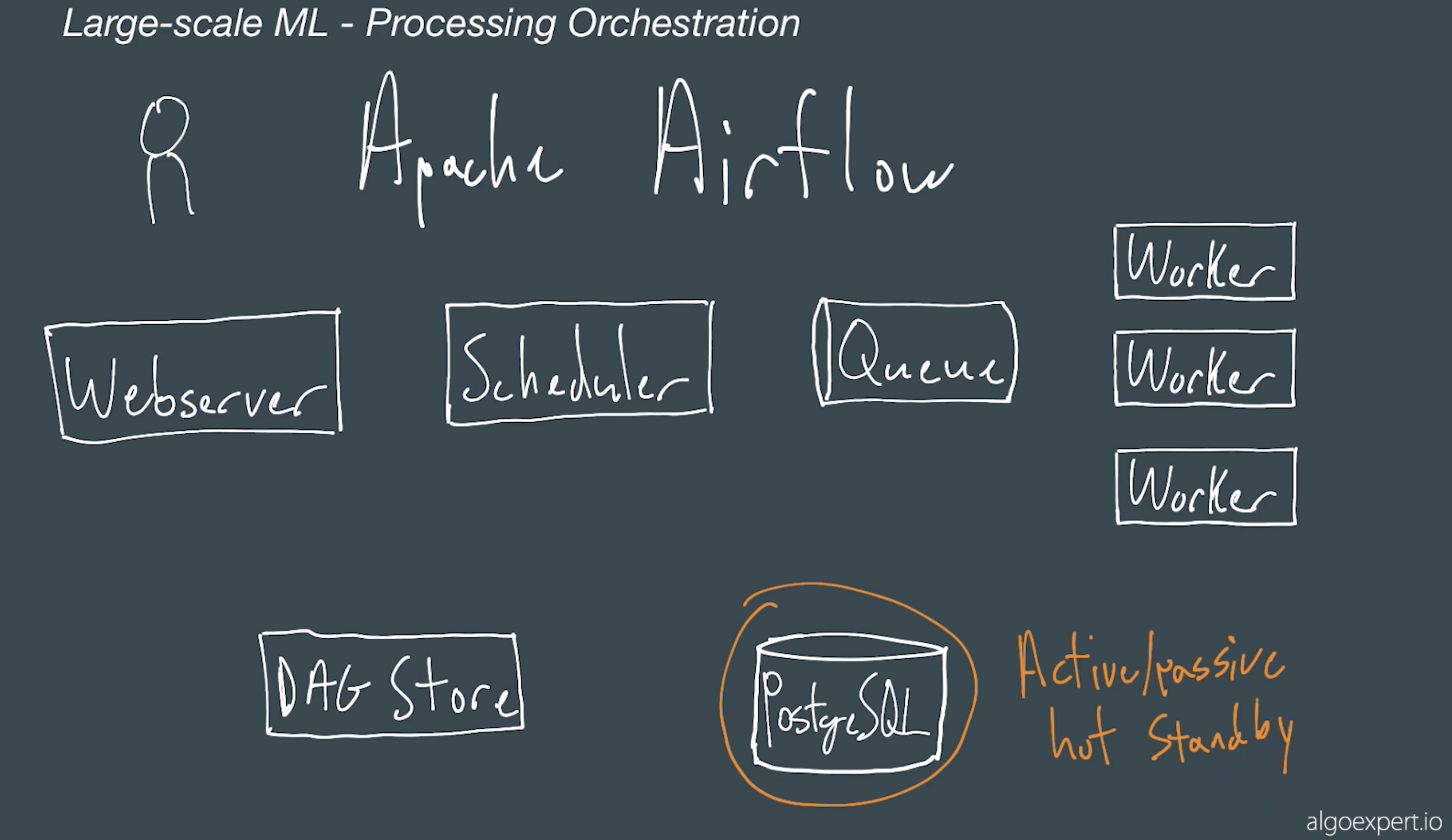
dags stored in s3 workers listen to celery queue Queue is usually a redis / rabbit mq queue