# Tflite
# Overview
Library that can help in
- reduce model size (less memory, faster download )
- fuse operation (faster operation)
Takes regular tensroflow SavedModel (protobuff) and compress it to a much lighter format based on FlatBuffers. FlatBuffers should lead to faster loading in memory
# How tp use
Tflite conversion
import tensorflow as tf
converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_path)
tflite_model = converter.convert()
with open("converted_model.tflite", "wb") as f:
f.write(tflite_model)
Usage in browser
import * as tf from '@tensorflow/tfjs';
const model = await tf.loadLayersModel('https://example.com/tfjs/model.json');
const image = tf.fromPixels(webcamElement);
const prediction = model.predict(image);
# Details in redution
- Remove / Fuse operation
Multiplication and addition can be rearranged to be more efficinet 3×a + 4×a + 5×a => (3 + 4 + 5)×a
Fuse operations like Batchnorm.
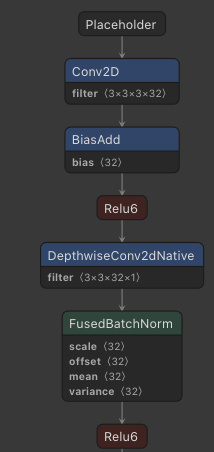
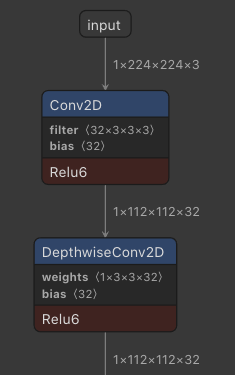
Above visiulaiztions were created witht netron (opens new window) using the mobilenet frozen buffer and tflite dwonload from tfhub (opens new window).
- Qunatization By default most model uses 32 bit float. If you convert to 16 bit float that would reduce the size.
Reference: https://www.tensorflow.org/lite/performance/model_optimization
Post Training Symmetric Quantization Lets say weights range from -1.5 to 0.8: Bytes –127, 0, and +127 will correspond to the floats –1.5, 0.0, and +1.5, respectively. 0.0 always maps to 0 when using symmetrical quantization byte values +68 to +127 will not be used, since they map to floats greater than +0.8)
Some systems like Edge TPU only support int quantization.
# References
GeÌron, A. (2019). Hands-on machine learning with Scikit-Learn, Keras and TensorFlow: concepts, tools, and techniques to build intelligent systems (2nd ed.). O’Reilly. Link (opens new window)