# Intro to Neural Networks
# Perceptron
# Intro
Perceptorn is one of the simplest Artificail Neural Netowrks.
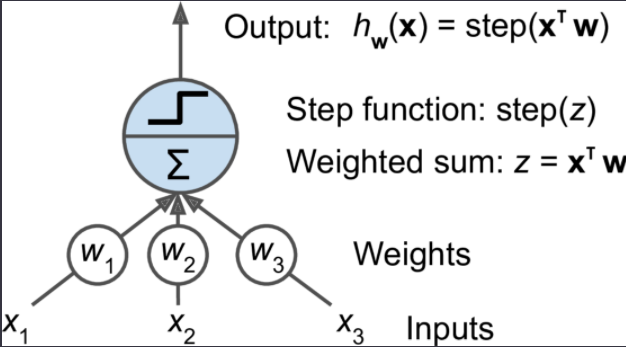 Source: Hands on Machine Learning
Source: Hands on Machine Learning
Common Step Functions:
 Source: Hands on Machine Learning
Source: Hands on Machine Learning
Perceptrons do not output a class probability like Logistic Regression.
# Perceptron Issues
Single Layer Perceptron can not solve the XOR problem. So, people lost interest.
Multiple Layers of network needed to replace the step function with something like sigmoid/relu/tan ; because it is differentiable.
# Sample Networks
# image classification
model = keras.models.Sequential([
keras.layers.Flatten(input_shape=[28, 28]),
keras.layers.Dense(300, activation="relu"),
keras.layers.Dense(100, activation="relu"),
keras.layers.Dense(10, activation="softmax")
])
model.compile(loss="sparse_categorical_crossentropy",
optimizer="sgd",
metrics=["accuracy"])
history = model.fit(X_train, y_train, epochs=30,
validation_data=(X_valid, y_valid))
y_proba = model.predict(X_new)
# Regression Network
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
housing = fetch_california_housing()
X_train_full, X_test, y_train_full, y_test = train_test_split(
housing.data, housing.target)
X_train, X_valid, y_train, y_valid = train_test_split(
X_train_full, y_train_full)
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_valid = scaler.transform(X_valid)
X_test = scaler.transform(X_test)
model = keras.models.Sequential([
keras.layers.Dense(30, activation="relu", input_shape=X_train.shape[1:]),
keras.layers.Dense(1)
])
model.compile(loss="mean_squared_error", optimizer="sgd")
history = model.fit(X_train, y_train, epochs=20,
validation_data=(X_valid, y_valid))
mse_test = model.evaluate(X_test, y_test)
X_new = X_test[:3] # pretend these are new instances
y_pred = model.predict(X_new)
Differences from classification:
- only one output node
- no activation function
- loss is mean squared error
# Wide and Deep Netowrk
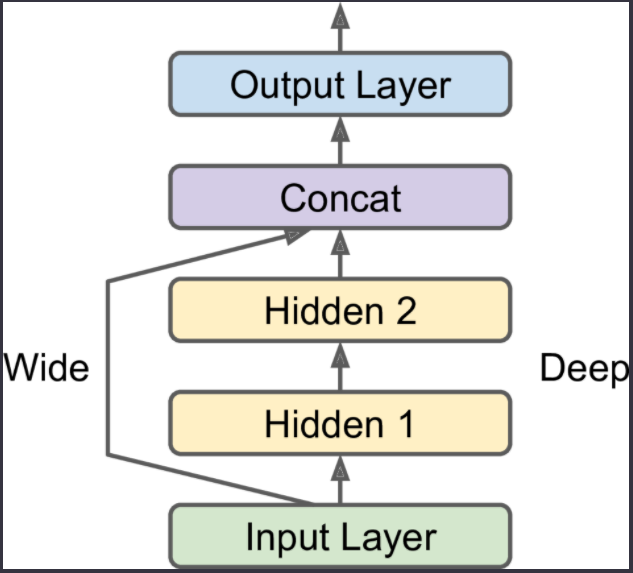
Input goes through hidden layers and to the output layer. Allows the network to learn deep patterns and simple rules.
input_ = keras.layers.Input(shape=X_train.shape[1:])
hidden1 = keras.layers.Dense(30, activation="relu")(input_)
hidden2 = keras.layers.Dense(30, activation="relu")(hidden1)
concat = keras.layers.Concatenate()([input_, hidden2])
output = keras.layers.Dense(1)(concat)
model = keras.Model(inputs=[input_], outputs=[output])
u can also use sublassing to represent model
class WideAndDeepModel(keras.Model):
def __init__(self, units=30, activation="relu", **kwargs):
super().__init__(**kwargs) # handles standard args (e.g., name)
self.hidden1 = keras.layers.Dense(units, activation=activation)
self.hidden2 = keras.layers.Dense(units, activation=activation)
self.main_output = keras.layers.Dense(1)
self.aux_output = keras.layers.Dense(1)
def call(self, inputs):
input_A, input_B = inputs
hidden1 = self.hidden1(input_B)
hidden2 = self.hidden2(hidden1)
concat = keras.layers.concatenate([input_A, hidden2])
main_output = self.main_output(concat)
aux_output = self.aux_output(hidden2)
return main_output, aux_output
model = WideAndDeepModel()
# Persisting
model = keras.models.Sequential([...]) # or keras.Model([...])
model.compile([...])
model.fit([...])
model.save("my_keras_model.h5")
model = keras.models.load_model("my_keras_model.h5")
# Callback
checkpoint_cb = keras.callbacks.ModelCheckpoint("my_keras_model.h5",
save_best_only=True)
early_stopping_cb = keras.callbacks.EarlyStopping(patience=10,
restore_best_weights=True)
history = model.fit(...,
callbacks=[checkpoint_cb,early_stopping_cb])
With EarlyStopping,you can set the number of epochs high and let the network stop , when after patient epochs , it dhoesn't improve.
# Other Notes
Loss:
sparse_categorical_crossentropyis when the label is 0-n and not one hot encoded.categorical_crossentropyis when the label is one hot encoeded.binary_crossentropybinary classification or multi label
Activation:
softmax: classificationsigmoid: binary or multilabel classification
Training Error is computed using a running mean during each epoch while validation error is computed at end of epoch.