# Lesson 5 : Convolutional Neural Networks
# Lectures
# Applications of CNNs
- WaveNet (opens new window)
- Text Classification (opens new window)
- Language Translation (opens new window)
- Play Atari games (opens new window)
- Play Pictionary (opens new window)
- Play Go (opens new window)
- CNNs powered Drone (opens new window)
- Self-Driving Car
- Predict depth from a single image (opens new window)
- Localize breast cancer (opens new window)
- Save endangered species (opens new window)
- Face App (opens new window)
# MNIST Dataset

- Most famous image dataset
# How Computers Interpret Images


We may want to normalize our image. Important preprocessing sterp.
It ensures that each input (each pixel value, in this case) comes from a standard distribution.
# Flattening an Image

# MLP (Multi Layer Perceptron) Structure & Class Scores

784 = 28*28 (each input pixel)
For MNIST problem , 1-2 hidden layers is sufficeint
# Loss & Optimization




# Training the Network
The steps for training/learning from a batch of data are described in the comments below:
- Clear the gradients of all optimized variables
- Forward pass: compute predicted outputs by passing inputs to the model
- Calculate the loss
- Backward pass: compute gradient of the loss with respect to model parameters
- Perform a single optimization step (parameter update)
- Update average training loss
# One Solution
model.eval()will set all the layers in your model to evaluation mode.- This affects layers like dropout layers that turn "off" nodes during training with some probability, but should allow every node to be "on" for evaluation.
- So, you should set your model to evaluation mode before testing or validating your model and set it to
model.train()(training mode) only during the training loop.
# Model Validation


# Validation Loss
- We create a validation set to:
- Measure how well a model generalizes, during training
- Tell us when to stop training a model; when the validation loss stops decreasing (and especially when the validation loss starts increasing and the training loss is still decreasing)
Although the model doesn't traion on the validation data, we are still using it to stop training
# Image Classification Steps

# MLPs vs CNNs

- MNIST already centered, real image can be any position
# Local Connectivity
Difference between MLP vs CNN
 input of 28284=784
If u have 1 hidden layer of 512 and 10 classes.. that equals 282851210 = 4millions params
input of 28284=784
If u have 1 hidden layer of 512 and 10 classes.. that equals 282851210 = 4millions paramsSparsely connected layer

Does every pixel need to be connected to every pixel? Parameter Sharing
# Filters and the Convolutional Layer
- CNN is special kind of NN that can remember spatial information
- The key to remember spatial information is convolutional layer, which apply series of different image filters (convolutional kernels) to input image

- CNN should learn to identify spatial patterns like curves and lines that make up number six

# Filters & Edges
Intensity is a measure of light and dark, similiar to brightness
To identify the edges of an object, look at abrupt changes in intensity
Filters
To detect changes in intensity in an image, look at groups of pixels and react to alternating patterns of dark/light pixels. Producing an output that shows edges of objects and differing textures.
Edges
Area in images where the intensity changes very quickly
# Frequency in Images
- High-frequency is a high pitched noise, like a bird chirp or violin.
- low frequency sounds are low pitch, like a deep voice or a bass drum.
- For sound, frequency actually refers to how fast a sound wave is oscillating; oscillations are usually measured in cycles/s (Hz), and high pitches and made by high-frequency waves.


- Frequency in images is a rate of change.
- on the scarf and striped shirt, we have a high-frequency image pattern
- parts of the sky and background that change very gradually, which is considered a smooth, low-frequency pattern
- High-frequency components also correspond to the edges of objects in images, which can help us classify those objects.
# High-pass Filters





- Edge Handling
- Extend Corner pixels are extended in 90° wedges. Other edge pixels are extended in lines.
- Padding The image is padded with a border of 0's, black pixels.
- Crop Any pixel in the output image which would require values from beyond the edge is skipped.
Quiz) Which kernel is best best for finding and enhancing horizontal edges and lines in an image?
 answer : d
answer : d
# Convolutional Layer
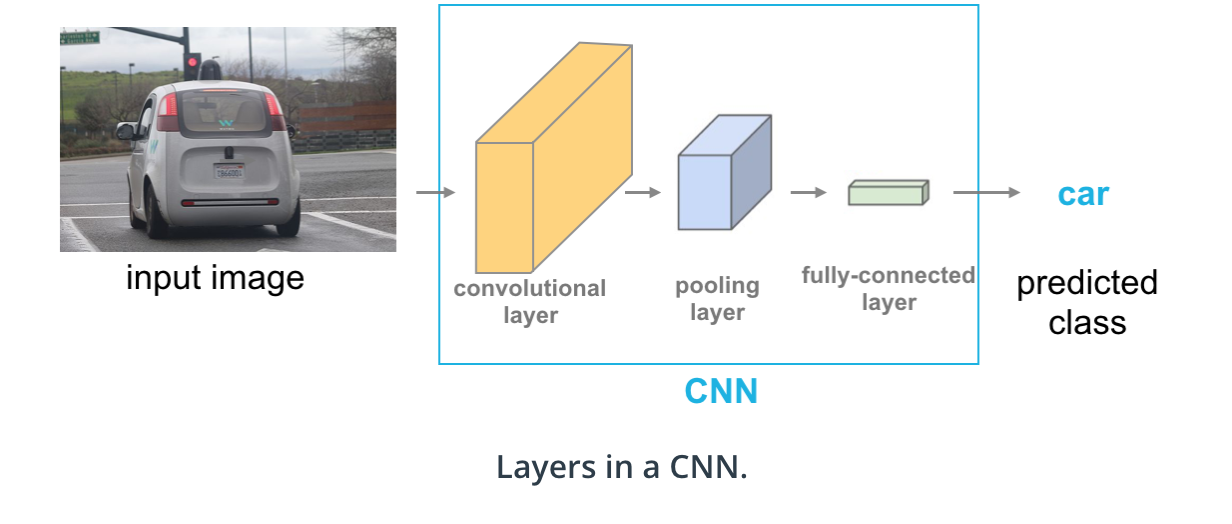
A CNN is composed of serveral of these layers:
- convolutaional
- pooling
- fully connected
Conviolutional Layer:
A layer of a deep neural network in which a convolutional filter passes along. A filter is just a matrix to detect some feature

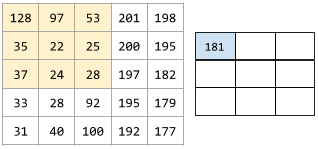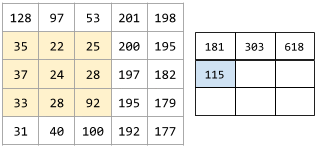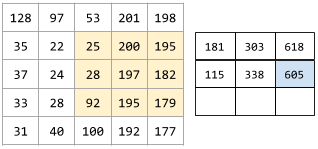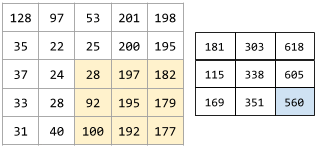
The following animation shows a convolutional layer consisting of 9 convolutional operations involving the 5x5 input matrix. Notice that each convolutional operation works on a different 3x3 slice of the input matrix. The resulting 3x3 matrix (on the right) consists of the results of the 9 convolutional operations:
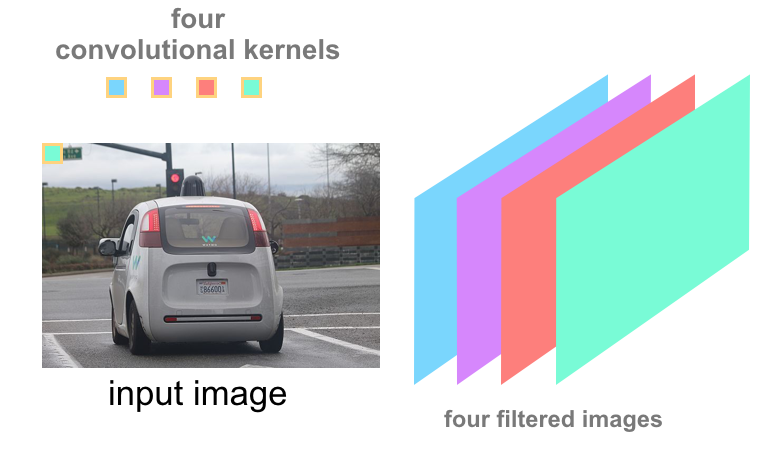
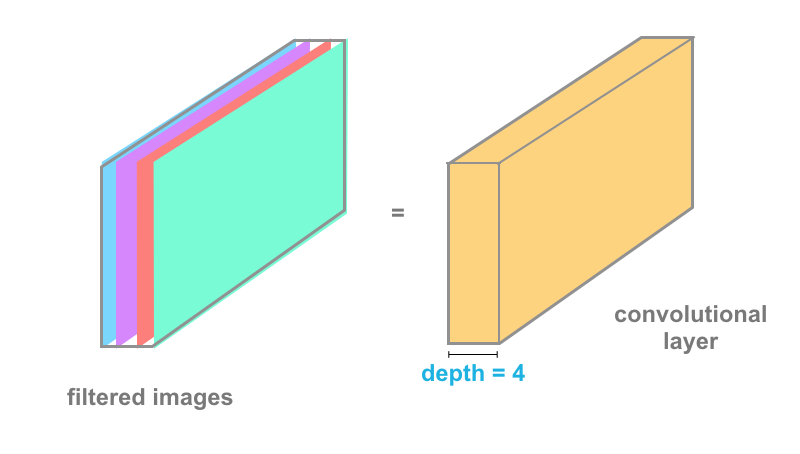
convolutional neural network
A neural network in which at least one layer is a convolutional layer. A typical convolutional neural network consists of some combination of the following layers:
- convolutional layers
- pooling layers
- dense layers
Convolutional neural networks have had great success in certain kinds of problems, such as image recognition.
# Convolutional Layers (Part 2)
- Grayscale image -> 2D Matrix
- Color image -> 3 layers of 2D Matrix, one for each channel (Red, Green, Blue)
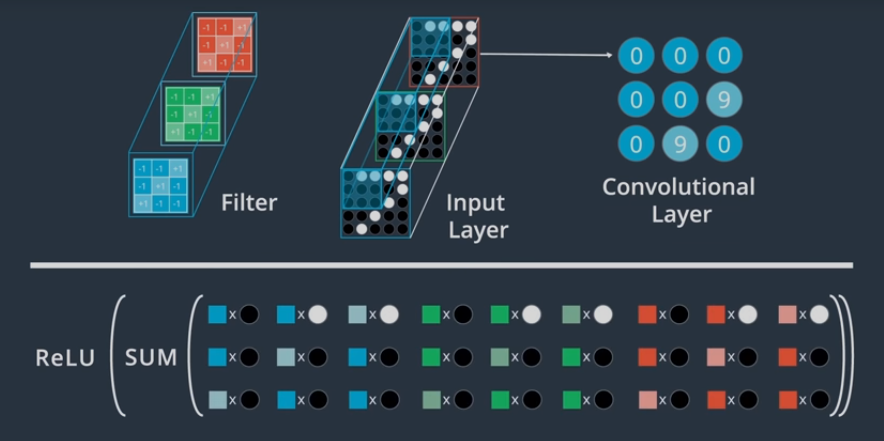
When people say layers/filters, they mean filter for each input layer.
So for a gray image, if we have n filters of 3x3, then we have n * (3x3) filters.
So, for a color image, if we have n fitlers, we actually have n* (333) filters
# Stride and Padding
Increase the number of node in convolutional layer -> increase the number of filter
increase the size of detected pattern -> increase the size of filter
Stride is the amount by which the filter slides over the image
Size of convolutional layer depend on what we do at the edge of our image
Padding give filter more space to move by padding zeros to the edge of image
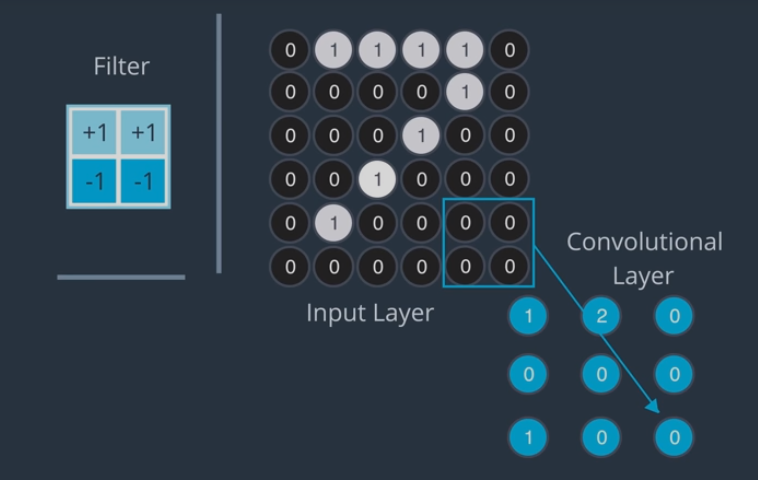
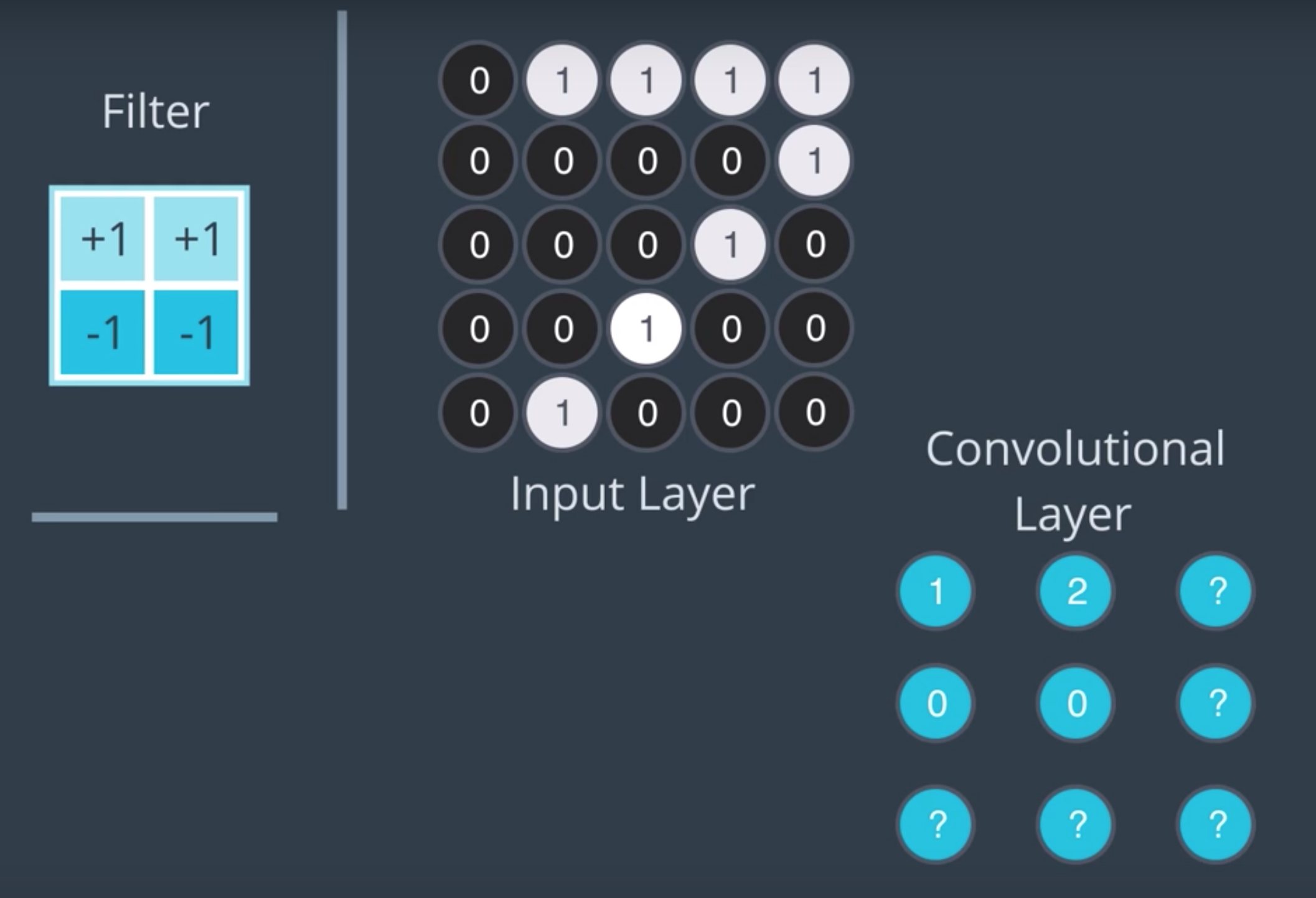 How do we deal with sides of the image, we could not apply the filter
How do we deal with sides of the image, we could not apply the filter
One option is to accept the filtered image will be smaaller (ignore those nodes).
The other option is to pad the image.
# Pooling Layers
pooling
Reducing a matrix (or matrices) created by an earlier convolutional layer to a smaller matrix. Pooling usually involves taking either the maximum or average value across the pooled area.
A pooling operation, just like a convolutional operation, divides that matrix into slices and then slides that convolutional operation by strides. F
Pooling helps enforce translational invariance in the input matrix.
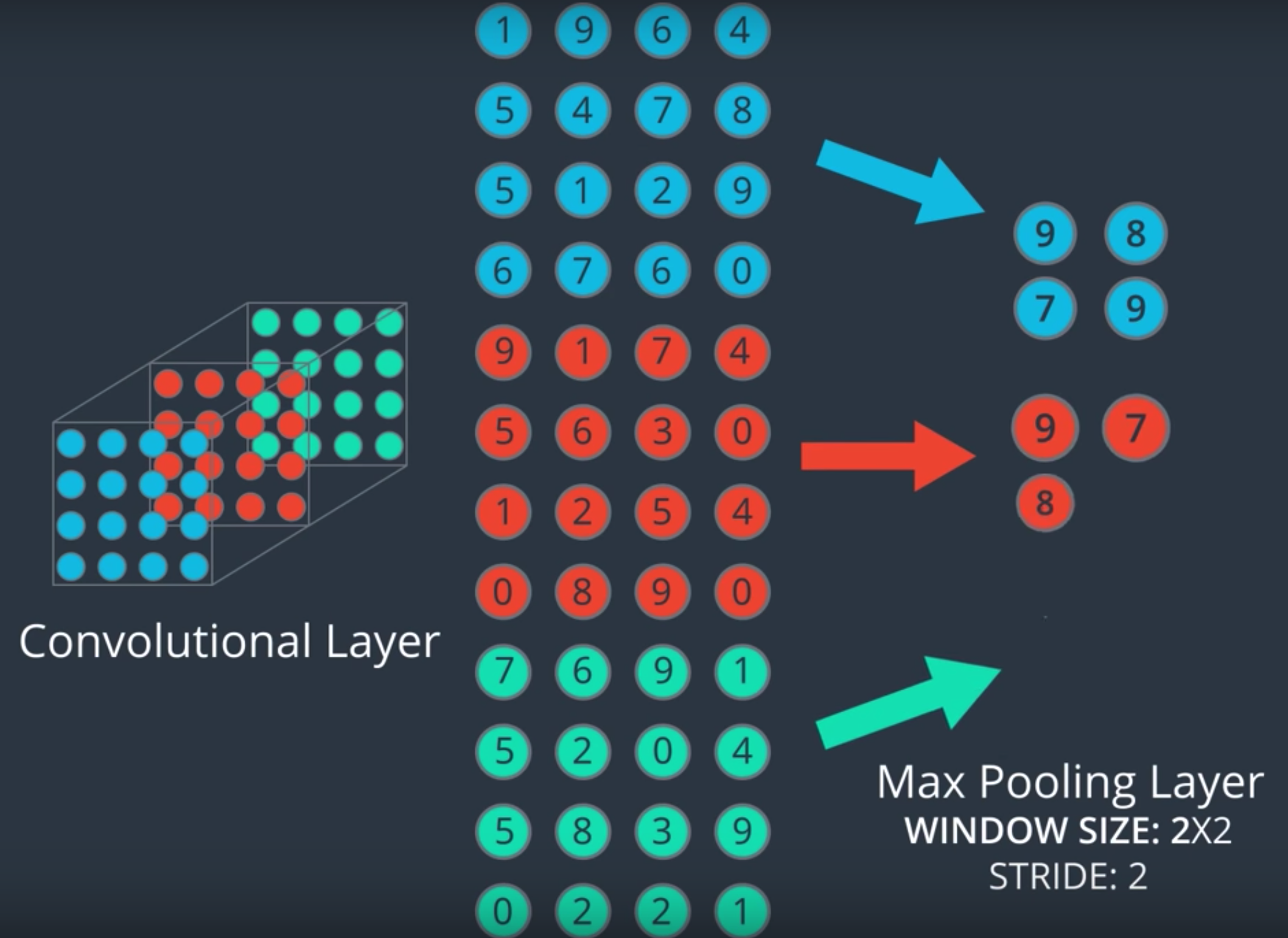
Pooling for vision applications is known more formally as spatial pooling. Time-series applications usually refer to pooling as temporal pooling. Less formally, pooling is often called subsampling or downsampling.
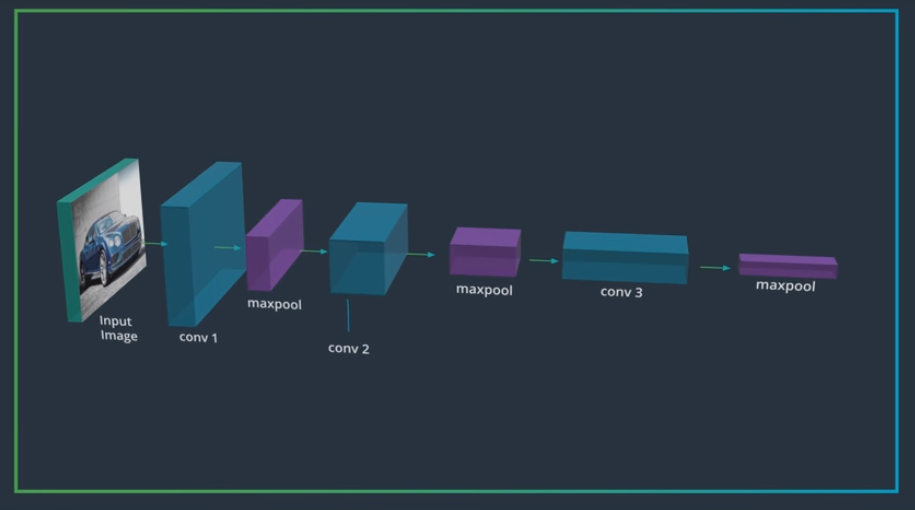
# Increasing Depth
- Incresing depth is actually:
- extracting more and more complex pattern and features that help identify the content and the objects in an image
- discarding some spatial information abaout feature like a smooth background that don't help identify the image
# CNNs for Image Classification

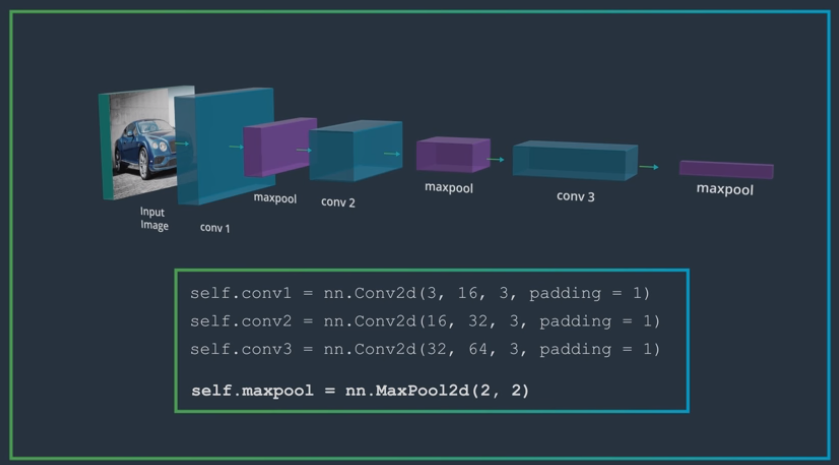
Quiz) How might you define a Maxpooling layer, such that it down-samples an input by a factor of 4?
- nn.MaxPool2d(2,4)
- nn.MaxPool2d(2,2)
- nn.MaxPool2d(4,4)
- nn.MaxPool2d(4,2)
Answer : A/C
The best choice would be to use a kernel and stride of 4, so that the maxpooling function sees every input pixel once, but any layer with a stride of 4 will down-sample an input by that factor.
Quiz) If you want to define a convolutional layer that is the same x-y size as an input array, what padding should you have for a kernel_size of 7? (You may assume that other parameters are left as their default values.)
Answer: padding=3
Yes! If you overlay a 7x7 kernel so that its center-pixel is at the right-edge of an image, you will have 3 kernel columns that do not overlay anything! So, that's how big your padding needs to be.
# Convolutional Layers in PyTorch
- init
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0)
in_channels refers to the depth of an input. For a grayscale image, this depth = 1
out_channels refers to the desired depth of the output, or the number of filtered images you want to get as output
kernel_size is the size of your convolutional kernel (most commonly 3 for a 3x3 kernel)
stride and padding have default values, but should be set depending on how large you want your output to be in the spatial dimensions x, y; default stride is 1 and default padding is 0
- forward
x = F.relu(self.conv1(x))
pooling layers
down sampling factors
self.pool = nn.MaxPool2d(2,2)- forward
x = F.relu(self.conv1(x)) x = self.pool(x)formula: number of parameters in a convolutional layer
K- number of filterF- filter sizeD_in- last value in theinput shape
(K * F*F * D_in) + KThe last K is because there is a bias for each filterformula: shape of a convolutional layer
K- number of filterF- filter sizeS- strideP- paddingW_in- size of prev layer
((W_in - F + 2P) / (S + 1)
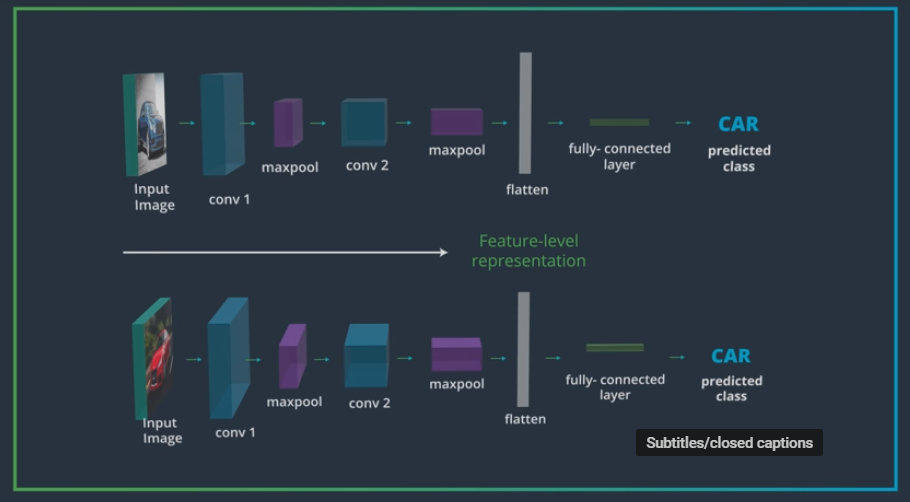
flattening
to make all parameters can be seen (as a vector) by a linear classification layer
# Feature Vector
- a representation that encodes only the content of the image
- often called a feature level representation of an image
# Image Augmentation
data augmentation Deep learning can overfit easily. If you want it to be robust, you should get images that depict the scenario it will be tested on.
If you can't you can augment your image by rotate, stretch, and reflect each image to produce many variants of the original picture, possibly yielding enough labeled data to enable excellent training.
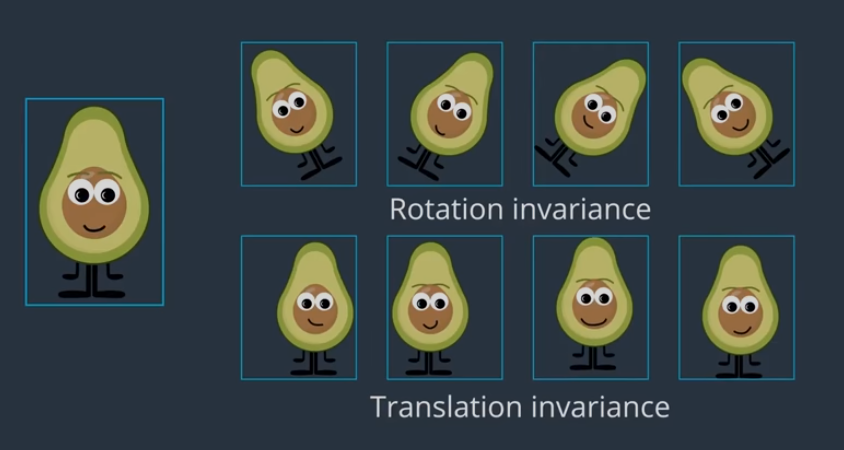
CNNS 's max pooling enables it to have translatiional invarince. If your image is not in the center.
# Summary of CNNs
- take input image then puts image through several convolutional and pooling layers
- result is a set of feature maps reduced in size from the original image
- flatten these maps, creating feature vector that can be passed to series of fully connected linear layer to produce probability distribution of class course
- from thes predicted class label can be extracted
- CNN not restricted to the image calssification task, can be applied to any task with a fixed number of outputs such as regression tasks that look at points on a face or detect human poses